A new ProgCity working paper (46) – Urban data power: capitalism, governance, ethics and justice – has been published. Download PDF
This working paper is a pre-print of Kitchin, R. (in press) Urban data power: capitalism, governance, ethics and justice. In Söderström, O. and Datta, A. (eds) Data Power in Action: Urban Data Politics in Times of Crisis. Bristol University Press.
Abstract
Urban big data systems are thoroughly infused with data power and data politics. These systems mobilise data power as a means to deepen the interests of states and their ability to manage urban life, and companies and their capacity to create and capture new markets and accumulate profit. Data power is thus deeply imbricated into the workings and reproduction of political economies, its deployment justified as a necessary means to tackle various urban crises and sustain growth. The paper details how data power is being claimed and exerted through the logics and practices of data capitalism, particularly with respect to urban platforms, and how data-driven systems are shifting the nature of governmentality and governance, enacting new, stronger forms of data power, as well as transferring some aspects of municipal government and service delivery to companies. The final section considers how data power can be resisted and reconfigured through an engagement with the ideas of data ethics, data justice, data sovereignty, and the practices of data activism.
Key words: urban data, smart city, capitalism, governance, governmentality, data ethics, data justice, data sovereignty
A new paper by Rob Kitchin titled ‘Conceptualising smart cities’ has been published in Urban Research and Practice. It consider how best to define smart cities and asks whether it is time to decentre and move beyond smart urbanism.
Kitchin, R. (2022) Conceptualising smart cities. Urban Research and Practice 15(1): 155-159. doi: 10.1080/17535069.2022.2031143
I had the pleasure of being a panellist for the Association of Internet Researchers (AoIR) plenary session yesterday, along with Helen Kennedy and Seeta Peña Gangadharan. I thought I’d share the text of my short presentation here.
In my time I want to focus on one part of the session descriptor, namely ‘how can we live well with data, rather than just survive.’ This is an issue that I’ve been giving some thought to and discuss at length in a recent book, Slow Computing: Why We Need Balanced Digital Lives, written with Alistair Fraser (available for the duration of the conference for £7 using the code SC20 at BUP website). Rather than simply critique how digital society is unfolding, we wanted to set out practical and political interventions which can be performed individually or collectively that push back against the negative aspects of living digital lives; that allow people to claim and assert some level of control and advocate for a different kind of digital world. In short, how can people live a ‘digital good life’, or as we put it in the book, ‘experience the joy and benefits of computing, but in a way that asserts individual and collective autonomy?’
In the book, we focus our attention on how our everyday lives have been transformed by digital technologies in two key respects.
The first is with respect to time and how networked devices have ushered in an era of network or instantaneous time, where people are always and everywhere available, encounters are organized on-the-fly, tasks become interleaved and multiply, there is working-time drift, and individuals can feel they are tied to a digital leash that leaves them harried and anxious. Technologies are altering the pace, tempo and temporal organization of digital life in ways that are not always to our benefit or well-being.
Our second concern is with respect to data and how increased datafication and dataveillance is enabling companies and states to profile, socially sort, target, nudge and manage us. How excessive data extraction is fuelling the growth of data capitalism and reshaping governance, governmentality and citizenship in ways that erode civil liberties. It is these issues, and living well with data, that I concentrate on here.
There is no doubt that the era of ubiquitous computing and big data has resulted in excessive data extraction. Many digital technologies and services practise ‘over-privileging’; that is, seeking permission to access more data and device functions than they need for their operation alone. This has eroded privacy, created new predictive privacy harms, expanded data markets and the ways in which companies can accumulation profit by leveraging value from personal data, and underpins new forms of technocratic, algorithmic, predictive and anticipatory governance. There is significant data power – expressed through data capitalism and the state’s use of data – that reproduce structural inequalities unevenly across people (related to class, gender, race, ethnicity, disability, etc.) and places (well-off and poorer neighbourhoods, regions, global north/south).
The question is what to do about this? Our answer is what we term ‘slow computing’, a term that draws on notions at the heart of the slow living movement – well-being, enjoyment, patience, quality, sovereignty, authenticity, responsibility, and sustainability. Slowness is about enacting a different kind of society, in our case both in relation to time and data. It is about using devices and apps without feeling harassed, stressed, coerced, or exploited; and it is about challenging and transforming iniquitous and exploitative structural relations.
Conceptually, our argument is underpinned by the concepts of an ethics of digital care, data justice, and time and data sovereignty. Rooted in the ideas and ideals of feminism, an ethics of digital care promotes moral action at the individual and collective level to ensure personal wellbeing and aid for others. It recognizes that we are bound within webs of responsibility, obligations and duties and advocates acting reciprocally and non-reciprocally to tackle data injustices. Data justice draws much of its moral argument from the ideas of social justice, seeks fair treatment of people through data-driven processes, and challenges data power in various ways, including data activism. Data sovereignty, rooted in the work of indigenous scholars, is the idea that we should retain some degree of authority, power and control over the data that relates to us, that we should also have a say in the mechanisms by which those data are extracted, and that other entities, such as companies and states, should recognize that sovereignty as legitimate.
Using these ideas we set out individual and collective tactics – both practical and political – for asserting data sovereignty and expressing an ethics of digital care. At an individual level, this includes various means to curate digital lives, use open source alternatives, step away from technologies, and obfuscate. At a collective level, it includes political campaigning and lobbying, placing pressure on companies, creating data commons, undertaking counter-data actions, producing open source, privacy enhancement tech and civic tech.
At the same time, we recognize that different groups of people have varying opportunities to practice slow computing; to live well with data. The ability to exert data sovereignty varies by class, gender, race, ethnicity, etc. Poorer and more marginalized populations are more often the focus of data power and are least able to resist and pushback. This is why a collective ethics of digital care is vital; to seek data justice for all.
Of course, we’re not the only folks thinking about this, with much of the work concerning data ethics, data justice and data activism seeking to envisage a different kind of digital society and push back against the worst excesses of dataveillance and data capitalism. However, there is much more theoretic, empirical, advocacy and activist work needed within and beyond the academy if we are to live well with data
The coronavirus pandemic has posed enormous challenges for governments seeking to delay, contain and mitigate its effects. Along with measures within health services, a range of disruptive public health tactics have been adopted to try and limit the spread of the virus and flatten the curve, including social distancing, self-isolation, forbidding social gatherings, limiting travel, enforced quarantining, and lockdowns. Across a number of countries these measures are being supplemented by a range of digital technologies designed to improve their efficiency and effectiveness by harnessing fine-grained, real-time big data. In general, the technologies being developed and rolled-out fall into four types: contact tracing, quarantine enforcement/movement permission, pattern and flow modelling, and symptom tracking. The Irish government is pursuing two of these – contact tracing and symptom tracking – merged into a single app ‘CovidTracker Ireland’. In this short essay, I outline what is known about the Irish approach to developing this app and assess whether it will work effectively in practice.
CovidTracker Ireland
On March 29th 2020 the Health Services Executive (HSE) announced that it hoped to launch a Covid-19 contact tracing app within a matter of days. Few details were given about the proposed app functionality or architecture, other than it would mimic other tracing apps, such as Singapore’s TraceTogether, using Bluetooth connections to record proximate devices and thus possible contacts, together with additional features for reporting well-being. The HSE made it clear that it would be an opt-in rather than compulsory initiative, that the app would respect privacy and GDPR, being produced in consultation with the Data Protection Commission, and it would be time-limited to the coronavirus response. It was not stated who would develop the app beyond it being described as a ‘cross-government’ effort.
On April 10th, the HSE revealed more details through a response to questions from Broadsheet.ie, stating that the now named CovidTracker Ireland App will:
“help the health service with its efforts in contact tracing for people who are confirmed cases;
allow a user to record how well they are feeling, or track their symptoms every day;
provide links to advice if the user has symptoms or is feeling unwell;
give the user up-to-date information about the virus in Ireland.”
Further, they reiterated that the app ‘will be designed in a way that maximises privacy as well as maximising value for public health. Privacy-by-design is a core principle underpinning the design of the CovidTracker Ireland App – which will operate on a voluntary and fully opt-in basis.’ There was no mention of the approach being taken; however the use of the HSE logo on the PEPP-PT (Pan-European Privacy-Preserving Proximity Tracing) website indicates that it has adopted that architecture, an initiative that claims seven countries are using their approach, with reportedly another 40 countries involved in discussions.
As of April 22nd the CovidTracker Ireland app is under development, with HSE stating on April 17th that it was being tested with a target of launching by early May when it is planned that some government restrictions will be lifted.
Critique and concerns
From the date it was announcement concerns have been expressed about the CovidTracker Ireland, particularly by representatives of Digital Rights Ireland and the Irish Council for Civil Liberties. A key issue has been the lack of transparency and openness in the approach being taken. An app will simply be launched for use without any published details of the approach and architecture being adopted, consultation with stakeholders, piloting by members of the public, and external feedback and assessment.
There are concerns that a centralized, rather than decentralized approach will be taken, and there is no indication that the underlying code will be open for scrutiny, if not by the public, at least by experts. It is not clear if the app is being developed in-house, or if it has been contracted out to a third-party developer and if the associated contract includes clauses concerning data ownership, re-use and sale, and intellectual property. There are no details about where data will be stored, who will have access to it, how will it be distributed, or how it be acted upon. There is unease as to whether the app will be fully compliant with GDPR and fully protect privacy, especially given that a Data Protection Impact Assessment (DPIA), which is legally required before launch, has seemingly not yet been undertaken. Such a DPIA would allow independent experts to be able to assess, validate and provide feedback and advice.
Critics are also concerned that CovidTracker Ireland merges the tasks of contact tracing and symptom tracking which have been pursued separately in other jurisdictions. Here, two sets of personal information are being tied together: proximate contacts and health measures. This poses a larger potential privacy problem if they are not adequately protected. Moreover, critics are worried that CovidTracker Ireland might become a ‘super app’, which extends its original ambition and goals. Here, the app might enable control creep, wherein it starts to be employed beyond its intended uses such as quarantine enforcement/movement permission. For example, Antoin O’Lachtnain of Digital Rights Ireland has speculated that we might eventually end up with an app to monitor covid-19 status that is “mandatory but not compulsory for people who deal with the public or work in a shared space.”
As Simon McGarr argues, the failure to adequately engage with these critiques and to be open and transparent means that “the launch of the app will inevitably be marred by immediately being the subject of questions and misinformation that could have been avoided by simply overcoming the State’s institutional impulse for secrecy.”
Internationally, there is scepticism concerning the method being used for app-based contact tracing and whether the critical conditions needed for successful deployment exist. Bluetooth does not have sufficient resolution to determine two metres or less proximity and using a timeframe to denote significant encounters potentially excludes fleeting, but meaningful contacts. There are also concerns with respect to representativeness (for example, 28% of people do not own a smartphone in Ireland), data quality, reliability, duping and spoofing, and rule-sets and parameters. The technical limitations are likely to lead to sizeable gaps and a large number of false positives that might produce an unmanageable signal-to-noise ratio, leading to unnecessary self-isolation measures and potentially overloading the testing system.
There is a concern that app-based contact tracing is being rushed to mass roll-out without it being demonstrated that it is fit-for-purpose. Moreover, the app will only be effective in practice if: there is a program of extensive testing to confirm that a person has the virus and if tracing is required; and 60% of the population participate to ensure reach across those who have been in close contact (c.80% of smartphone users). The symptom tracking relies on self-reporting, which lacks rigour and, as testing has shown, a large proportion of the population who were tested because they were experiencing symptoms returned negative. This is likely to lead to a large number of false positives and it is doubtful that these data should guide contact tracing.
At present, while Ireland is ramping up its testing capability towards 100,000 tests a week, it might need to increase that further. The Edmond J. Safra Center for Ethics at Harvard University suggest that in the United States: “We need to deliver 5 million tests per day by early June to deliver a safe social reopening. This number will need to increase over time (ideally by late July) to 20 million a day to fully remobilize the economy. We acknowledge that even this number may not be high enough to protect public health.” The equivalent rate for Ireland would be 300,000 tests per day. In Singapore, only 12% of people have registered to use the TraceTogether app, which raises doubts as to whether 60% of the population in Ireland will participate, especially since the public are primed to be sceptical given media coverage about the app have raised issues of privacy, data security and data usage.
Will CovidTracker Ireland work and what needs to happen?
There is unanimous agreement that contact tracing is a cornerstone measure for tackling pandemics. Assuming that the privacy and data protection issues can be adequately dealt with it, it would be good to think that CovidTracker Ireland will make a difference to containing the coronavirus and stopping any additional waves of infection.
However, there are reasons to doubt that app-based contact tracing and symptom tracking will make the kind of impact hoped for unless:
its technical approach is sound and civil liberties protected;
there is testing at sufficient scale that potential cases, including false ones, are dealt with quickly;
the government can persuade people to participate in large numbers.
The government might also have to supply smartphones to those that do not own them, as they did in Taiwan. Persuading people to participate will especially be a challenge since the government is not being sufficiently transparent at present in explaining the approach being taken, the app’s intended technical specification, how it will operate in practice, its procedures for oversight, and how it will protect civil liberties.
It is essential that the government follow the guidance of the European Data Protection Board that recommends that strong measures are put in place to protect privacy, data minimization is practised, the source code is published and regularly reviewed, there is clear oversight and accountability, and there is purpose limitation that stops control creep.
If implemented poorly, the app could have a profound chilling effect on public trust and public health measures that might be counterproductive. As a consequence, the Ada Lovelace Institute, a leading UK centre for artificial intelligence research, is advising governments to be cautious, ethical and transparent in their use of app-based contact tracing. Ireland might do well to heed their advice.
Update: a revised version of this working paper has now been published as open access in Space and Polity.
A new paper by Rob Kitchin (Programmable City Working Paper 44) examines whether digital technologies will be effective in tackling the spread of the coronavirus, considers their potential negative costs vis-a-vis civil liberties, citizenship, and surveillance capitalism (see table below), and details what needs to happen.
Using digital technologies to tackle the spread of the coronavirus: Panacea or folly?
Abstract
Digital technology solutions for contact tracing, quarantine enforcement (digital fences) and movement permission (digital leashes), and social distancing/movement monitoring have been proposed and rolled-out to aid the containment and delay phases of the coronavirus and mitigate against second and third waves of infections. In this essay, I examine numerous examples of deployed and planned technology solutions from around the world, assess their technical and practical feasibility and potential to make an impact, and explore the dangers of tech-led approaches vis-a-vis civil liberties, citizenship, and surveillance capitalism. I make the case that the proffered solutions for contact tracing and quarantining and movement permissions are unlikely to be effective and pose a number of troubling consequences, wherein the supposed benefits will not outweigh potential negative costs. If these concerns are to be ignored and the technologies deployed, I argue that they need to be accompanied by mass testing and certification, and require careful and transparent use for public health only, utilizing a privacy-by-design approach with an expiration date, proper oversight, due processes, and data minimization that forbids data sharing, repurposing and monetization.
Keywords: coronavirus; COVID-19; surveillance; governmentality; citizenship; civil liberties; contact tracing; quarantine; movement; technological solutionism; spatial sorting; social sorting; privacy; control creep; data minimization; surveillance capitalism; ethics; data justice.
I attended the Smart Cities and Regions Summit in Croke Park, Dublin, today and took part in the ‘smart spaces and smart citizens?’ panel. We were asked to produce a short opening statement and thought I’d share it here.
I’m going to discuss smart citizens by considering Dublin as a smart city. To start, I want to ask you a set of questions which I’d like you to respond to by raising a hand. Don’t be shy; this requires participation.
How many of you have a good idea as to what Smart Dublin is and what it does?
How many of you feel you have a good sense of smart city developments taking place in Dublin?
Would you be able to tell me much about the 100+ smart city projects that are taking place in the city in conjunction with Smart Dublin and it four local authority partners?
Would you be able to tell me much about the extent to which these projects engage with citizens?
Or how the technologies used impact citizens, either in direct or implicit ways?
Or whether Smart Dublin and the four local authorities have a guiding set of principles or a programme for citizen engagement or smart citizens?
You’re all people interested in smart cities. You’re here because it relates to your work in some way. You have a vested interest in knowing about smart cities.
Do you think that citizens in Dublin know about these projects, which might be taking place in their locality?
Do you think that they have sufficient knowledge to be able judge, in an informed way, a project’s merits?
Do you think they have an active voice in these projects’ conception, their deployment, the work that they do? In how any data generated are processed, analysed, shared, stored, and value extracted, etc.?
Do local politicians – citizen representatives – know about them? And do they have an active voice in smart city development in Dublin?
This panel is titled ‘Smart spaces and smart citizens’.
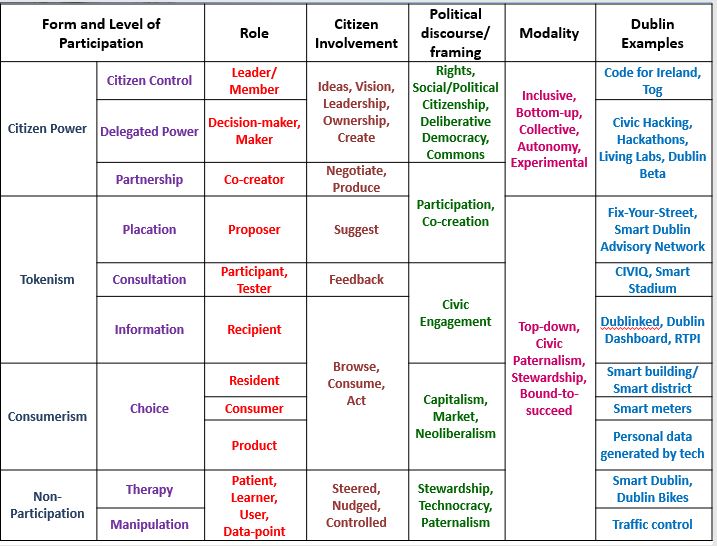
What is difficult to see in most smart city initiatives is the ‘smart citizen’ element. It seems that what is implied by ‘smart citizen’ is simply being a person living in a city where smart city technology is deployed, or being a person that uses networked digital technology as part of everyday life.
To create a smart citizen, all a state body or company apparently needs to do is say people should be at the heart of things, or enact a form of stewardship (deliver a service on behalf of citizens) and civic paternalism (decide what’s best for citizens), rather than citizens being meaningfully involved in the vision and development of the smart city.
In our own research concerning networked urbanism and smart cities from a social sciences perspective we have been interested in exploring these kinds of questions, and how the citizen fits into the smart city. It’s a central concern in our latest book published next month, ‘The Right to the Smart City’, which explores the smart city in relation to notions of citizenship and social justice.
What our research shows is that citizens can be varyingly positioned, and perform very different roles, in the smart city depending on the type of initiative.
It is perhaps no surprise then that citizens in numerous jurisdictions have started to push back against the more technocratic, top-down, marketised versions of the smart city – the on-going protests in Toronto over the Sidewalk Labs waterfront development being a prominent example. Instead, they demand more inclusive, empowering and democratic visions, with Barcelona’s notion of technological sovereignty often providing inspiration (see my recent piece comparing Toronto and Barcelona and links to articles and organisation websites).
It is difficult to argue that we are enabling ‘smart citizens’ if they are not informed, consulted or involved in the development and roll-out of smart city initiatives. As such, if we are truly interested in creating smart citizens then we need to make a meaningful move beyond the dominant tropes of stewardship and civic paternalism to approach smart cities in a smarter way.
For a fuller discussion see the opening and closing chapters of The Right to the Smart City, which are available as open access versions.
Kitchin, R., Cardullo, P. and di Feliciantonio, C. (2018) Citizenship, Social Justice and the Right to the Smart City. Pre-print Chapter 1 in The Right to the Smart City edited by Cardullo, P., di Feliciantonio, C. and Kitchin, R. Emerald, Bingley.
Kitchin, R. (2018) Towards a genuinely humanizing smart urbanism. Pre-print Chapter 14 in The Right to the Smart City edited by Cardullo, P., di Feliciantonio, C. and Kitchin, R. Emerald, Bingley.