Abstract
Digital technologies of various kinds are now the means through which many cities are made visible and their spatialities negotiated. From casual snaps shared on Instagram to elaborate photo-realistic visualisations, digital technologies for making, distributing and viewing cities are more and more pervasive. This talk will explore some of the implications of that digital mediation of urban spaces. What forms of urban life are being made visible in these digitally mediated cities, and how? Through what configurations of temporality, spatiality and embodiment? And how should that picturing be theorised? Drawing on recent work on the visualisation of so-called ‘smart cities’ on social media, the lecture will suggest the scale and pervasiveness of digital imagery now means that notions of ‘representation’ have to be rethought. Cities and their inhabitants are increasingly mediated through a febrile cloud of streaming image files; as well as representing cities, this cloud also operationalises particular, affective ways of being urban. The lecture will explore some of the implications of this shift for both theory and method as well as critique.
We are very excited to announce that our next seminar will feature Professor Gillian Rose (Oxford University), jointly organised with Social Sciences Institute and Geography Department. The seminar is entitled: Tweeting the Smart city: The Affective Enactments of the Smart City on Social Media and you can find further seminar details below. We look forward to seeing many of you in the seminar!
Time: 13:00 to 14.30, Thursday, 26th October Venue: Rocque Lab, Rhetoric House, South Campus, Maynooth University (Building #17 on the campus map) Abstract:
Digital technologies of various kinds are now the means through which many cities are made visible and their spatialities negotiated. From casual snaps shared on Instagram to elaborate photo-realistic visualisations, digital technologies for making, distributing and viewing cities are more and more pervasive. This talk will explore some of the implications of that digital mediation of urban spaces. What forms of urban life are being made visible in these digitally mediated cities, and how? Through what configurations of temporality, spatiality and embodiment? And how should that picturing be theorised? Drawing on recent work on the visualisation of so-called ‘smart cities’ on social media, the lecture will suggest the scale and pervasiveness of digital imagery now means that notions of ‘representation’ have to be rethought. Cities and their inhabitants are increasingly mediated through a febrile cloud of streaming image files; as well as representing cities, this cloud also operationalises particular, affective ways of being urban. The lecture will explore some of the implications of this shift for both theory and method as well as critique.
A new book chapter by Rob Kitchin has been published in The Sage Handbook of Social Media Research Methods edited by Luke Sloan and Anabel Quan-Haase. The chapter is titled ‘Big data – hype or revolution’ and provides a general introduction to big data, new epistemologies and data analytics, with the latter part focusing on social media data. The text below is a sample taken from a section titled ‘The limits of social media big data’.
The discussion so far has argued that there is something qualitatively different about big data from small data and that it opens up new epistemological possibilities, some of which have more value than others. In general terms, it has been intimated that big data does represent a revolution in measurement that will inevitably lead to a revolution in how academic research is conducted; that big data studies will replace small data ones. However, this is unlikely to be the case for a number of reasons.
Whilst small data may be limited in volume and velocity, they have a long history of development across science, state agencies, non-governmental organizations and business, with established methodologies and modes of analysis, and a record of producing meaningful answers. Small data studies can be much more finely tailored to answer specific research questions and to explore in detail and in-depth the varied, contextual, rational and irrational ways in which people interact and make sense of the world, and how processes work. Small data can focus on specific cases and tell individual, nuanced and contextual stories.
Big data is often being repurposed to try and answer questions for which it was never designed. For example, geotagged Twitter data have not been produced to provide answers with respect to the geographical concentration of language groups in a city and the processes driving such spatial autocorrelation. We should perhaps not be surprised then that it only provides a surface snapshot, albeit an interesting snapshot, rather than deep penetrating insights into the geographies of race, language, agglomeration and segregation in particular locales. Moreover, big data might seek to be exhaustive, but as with all data they are both a representation and a sample. What data are captured is shaped by: the field of view/sampling frame (where data capture devices are deployed and what their settings/parameters are; who uses a space or media, e.g., who belongs to Facebook); the technology and platform used (different surveys, sensors, lens, textual prompts, layout, etc. all produce variances and biases in what data are generated); the context in which data are generated (unfolding events mean data are always situated with respect to circumstance); the data ontology employed (how the data are calibrated and classified); and the regulatory environment with respect to privacy, data protection and security (Kitchin, 2013, 2014a). Further, big data generally capture what is easy to ensnare – data that are openly expressed (what is typed, swiped, scanned, sensed, etc.; people’s actions and behaviours; the movement of things) – as well as data that are the ‘exhaust’, a by-product, of the primary task/output.
Small data studies then mine gold from working a narrow seam, whereas big data studies seek to extract nuggets through open-pit mining, scooping up and sieving huge tracts of land. These two approaches of narrow versus open mining have consequences with respect to data quality, fidelity and lineage. Given the limited sample sizes of small data, data quality – how clean (error and gap free), objective (bias free) and consistent (few discrepancies) the data are; veracity – the authenticity of the data and the extent to which they accurately (precision) and faithfully (fidelity, reliability) represent what they are meant to; and lineage – documentation that establishes provenance and fit for use; are of paramount importance (Lauriault, 2012). In contrast, it has been argued by some that big data studies do not need the same standards of data quality, veracity and lineage because the exhaustive nature of the dataset removes sampling biases and more than compensates for any errors or gaps or inconsistencies in the data or weakness in fidelity (Mayer-Schonberger and Cukier, 2013). The argument for such a view is that ‘with less error from sampling we can accept more measurement error’ (p.13) and ‘tolerate inexactitude’ (p. 16).
Nonetheless, the warning ‘garbage in, garbage out’ still holds. The data can be biased due to the demographic being sampled (e.g., not everybody uses Twitter) or the data might be gamed or faked through false accounts or hacking (e.g., there are hundreds of thousands of fake Twitter accounts seeking to influence trending and direct clickstream trails) (Bollier, 2010; Crampton et al., 2012). Moreover, the technology being used and their working parameters can affect the nature of the data. For example, which posts on social media are most read or shared are strongly affected by ranking algorithms not simply interest (Baym, 2013). Similarly, APIs structure what data are extracted, for example, in Twitter only capturing specific hashtags associated with an event rather than all relevant tweets (Bruns, 2013), with González-Bailón et al. (2012) finding that different methods of accessing Twitter data – search APIs versus streaming APIs – produced quite different sets of results. As a consequence, there is no guarantee that two teams of researchers attempting to gather the same data at the same time will end up with identical datasets (Bruns, 2013). Further, the choice of metadata and variables that are being generated and which ones are being ignored paint a particular picture (Graham, 2012). With respect to fidelity there are question marks as to the extent to which social media posts really represent peoples’ views and the faith that should be placed on them. Manovich (2011: 6) warns that ‘[p]eoples’ posts, tweets, uploaded photographs, comments, and other types of online participation are not transparent windows into their selves; instead, they are often carefully curated and systematically managed’.
There are also issues of access to both small and big data. Small data produced by academia, public institutions, non-governmental organizations and private entities can be restricted in access, limited in use to defined personnel, or available for a fee or under license. Increasingly, however, public institution and academic data are becoming more open. Big data are, with a few exceptions such as satellite imagery and national security and policing, mainly produced by the private sector. Access is usually restricted behind pay walls and proprietary licensing, limited to ensure competitive advantage and to leverage income through their sale or licensing (CIPPIC, 2006). Indeed, it is somewhat of a paradox that only a handful of entities are drowning in the data deluge (boyd and Crawford, 2012) and companies such as mobile phone operators, app developers, social media providers, financial institutions, retail chains, and surveillance and security firms are under no obligations to share freely the data they collect through their operations. In some cases, a limited amount of the data might be made available to researchers or the public through Application Programming Interfaces (APIs). For example, Twitter allows a few companies to access its firehose (stream of data) for a fee for commercial purposes (and have the latitude to dictate terms with respect to what can be done with such data), but with a handful of exceptions researchers are restricted to a ‘gardenhose’ (c. 10 percent of public tweets), a ‘spritzer’ (c. one percent of public tweets), or to different subsets of content (‘white-listed’ accounts), with private and protected tweets excluded in all cases (boyd and Crawford, 2012). The worry is that the insights that privately owned and commercially sold big data can provide will be limited to a privileged set of academic researchers whose findings cannot be replicated or validated (Lazer et al., 2009).
Given the relative strengths and limitations of big and small data it is fair to say that small data studies will continue to be an important element of the research landscape, despite the benefits that might accrue from using big data such as social media data. However, it should be noted that small data studies will increasingly come under pressure to utilize the new archiving technologies, being scaled-up within digital data infrastructures in order that they are preserved for future generations, become accessible to re-use and combination with other small and big data, and more value and insight can be extracted from them through the application of big data analytics.
The advent of discourses around the ‘smart city’, big data, open data, urban analytics, the introduction of ‘smarter technology’ within cities, the sharing of real-time information, and the emergence of social media platforms has had a number of outcomes on emergency services worldwide. Together they provide opportunities and promises for emergency services regarding efficiency, community engagement and better real-time coordination. Thus, we are seeing a growth in technologically based emergency response. However, such developments are also riddled with broad concerns, ranging from privacy, ethics, reliability, accessibility, staff reluctance and fear.
This post considers one recent technological push for the re-invention of the emergency call system (911bot) and another for the sharing of real-time information during a major event (Smartphone Terror Alert).
911bot
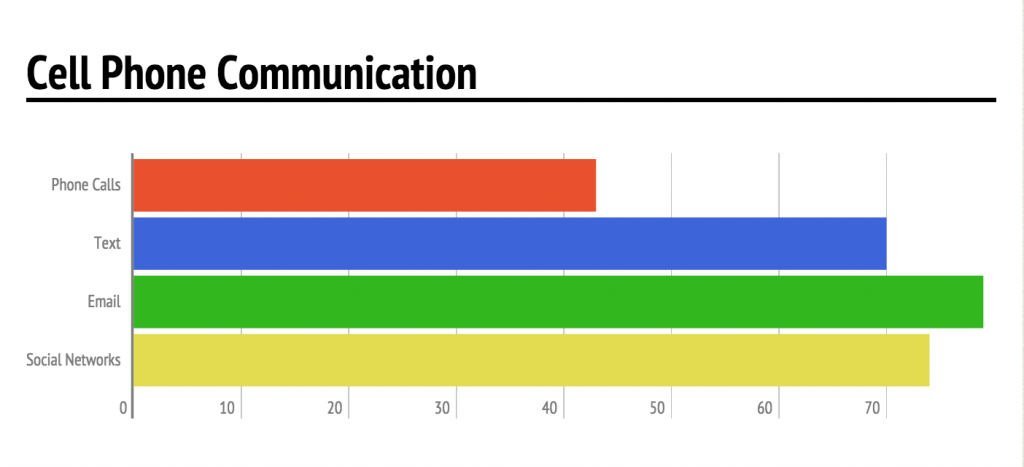
In recent years, there has been a significant move away from voice calls towards texting and internet based platforms (eg.WhatsApp and Twitter)(see figure 1), this is tracked regularly by the International Smartphone Mobility Report conducted across 12 countries by the data tracking company Infomate. In 2015, they found that in America the average time spent on voice calls was 6 minutes as opposed to 26 minutes texting, and worldwide, internet based platforms were the main form of communication (Infomate, 2015 and Shrapshire, 2015).
Figure 1: Cell phone Communication. Source: Russell (2015).
In light of this, there is a push by both the private sector and entrepreneurs to utilise mobile phones and social media platforms in new ways such as within the emergency call system. Within my own field research, I have questioned first responders in Ireland and the US regarding the use of social media and apps as alternative means to the current telephone system. For the most part, this was met with disdain and confusion from first responders. Strong arguments were made against a move away from a call-dominated response system. These included:
a) Difficulty in obtaining relevant and accurate information regarding the event, including changing conditions and situations.
b) Not able to provide the victim or caller with accurate instructions and information.
c) Restrictions in contacting the caller.
d) The system would need an overhaul for it to work, i.e. a dedicated team ensuring that these messages are not missed, and require staff training.
e) Call systems are established mechanisms for contacting the emergency services, why change it when it works?
f) If you use something like Twitter or Facebook to report an emergency how do we ensure that it is reported correctly and not just tweeted or messaged to an interface which is not monitored 24/7?
And as can be seen through the following conversation with two operational first responders in Dublin, Ireland, they want new technology but are also highly hesitant as to its ability to ensure a quick response.
Conversation between researcher and two first responders
R1: See the problem with a tweet and a text, I can’t get any information out of that, like I could tweet and back and then you are waiting for them to send something back, when I have you on the phone, I can question you, “What is it?”, “What is wrong?”, “What is the problem?”.
R2: If you did go with something like [social media platform for emergency call intake], you would have to have the likes of, if you are the tweet man then you would have to be 100% on the phone looking at it
R2: It probably would work if it wasn’t an emergency as such, not a full emergency
R1: I think people need tobe re-assured that someone has seen it and really knows what is happening.
R1: Jesus you could have everyone tweeting saying I have a sore stomach and that would register as a call for us so the calls would just get worse and worse. […] I think if you ring Domino Pizza now, it will know who you are, where you are and your order
R2: They can read the caller ID coming
R1:We haven’t got that
All of these are understandable concerns, but they also illustrate a resistance to innovative change that may result in cultural and institutional change which they oppose due to highly legitimate fears of effectiveness and reliability. Even so, they are welcoming of technology which has obvious benefits for them such as the “Domino’s Pizza” caller ID system, but are more reluctant towards innovations such as the 911bot whose value is overshadowed by fears of inefficiency, information gaps and reliability. However, the 911bot does potentially address some of these issues within its design.
The 911bot (figure 2) was developed during TechCrunch’s Disrupt Hackathon in New York in 2016. It works through Facebook Messenger, which had a reported 1 billion users in July 2016 (Costine, 2016), to allow users to report an emergency. Initially, one would be forgiven for immediately thinking of the arguments made against a transformation of the current system as presented above. However, the messenger app already offers location services based on the phones GPS thus, when reporting an incident, your exact location is immediately sent (although you can turn off your GPS signal and restrict your location being sent, when using this bot there is potential for that to be overridden). The person reporting the incident can also send pictures or videos and the bot can provide information on what you should and shouldn’t do in that situation such as, how to do CPR during a cardiac arrest (Westlake, 2016).
Further, this bot has potential to feedback the location of the first responders to the reporter. It provides the control room with more accurate information coming from real-time videos and pictures meaning that they are not relying wholly on information from untrained and scared people. And, most importantly, this system doesn’t take away from the control room interacting with the caller. From the information provided by the developers, it appears that once the messenger sends the request, the control room calls the phone and resumes their role but with more information. Possibly, going forward this could even be done through Facetime so that the control room has live interaction with the event prior to the arrival of the first responders. Although, the 911bot has only been developed and not deployed, in time and after much consultation and experimentation, it could prove very beneficial within emergency response. For instance, if the control room operator can actually see how the person is conducting CPR, can see and hear their breathing, see the extent of the injury, fire, or road traffic collision in real time, it would inform decision-making that could create better and more efficient responses. However, it would be remiss to discuss this without noting that there are potential privacy issues with the mass use of this type of technology outside of the remit of this post, that would need to be considered.
Figure 2: 911bot. Source: 911bot online.
Smartphone Terror Alert
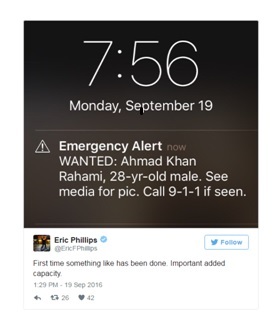
Another new use of mobile technology was the mass terror alert issued on September 17th 2016, after Chelsea, Manhattan was hit with an explosion. The alert (figure 3) was issued by the Office of Emergency Management, New York Police Department and the FBI through all phone networks. It was received by an unknown number of people and provided information about the key suspect – Ahmed Khan Rahami. The Press secretary for New York Mayor Bill de Blasio stated that it was the first use of this alert at a “mass scale” and as the suspect was caught within 3 hours, it presented the appearance that this alert was effective, with New York’s Police Commissioner stating “it was the future”(Fiegerman, 2016). Yet there is no evidence that the alert had anything to do with the catching of the suspect; these two factors could be circumstantial.
Figure 3: Smart phone terror Alert. Source: published in Fiegerman (2016).
Further, as illustrated by Anil Dash in Fiegerman (2016) how effective was it actually? “Is there evidence that low-information untargeted push notifications help with any kind of crime? Seems they’re more optimised for panic”. This is compounded by the lack of an all-clear alert, which would work to ease tensions and potential panic. We live in a socially constructed risk society (Beck, 1992; 2009) and with innovations such as this, even if the intention is good, the potential for mass panic is created, which raises questions regarding the appropriateness of this mechanism. In this instance, sending an alert with little information, using just a name, makes everyone who could fit that name a potential target, and is an action that could create panic, fear and racial attacks under the illusion of “citizen arrest”. However, this system has potential especially if it were utilised during severe weather events to provide information on evacuation centres and resources rather than during more sensitive events such as a manhunt. Essentially, though, before it can be deemed thoroughly effective and safe there needs to be stringent supportive policy and agency and community training to ensure that response from agencies as well as communities is coordinated and effective rather than panicked and uninformed. So, I wonder, is this really the future, and indeed, does it need to be the future? Is it already the present with no sense of reflection on the potential consequences of such a system by the lead federal and local emergency agencies and institutions? I don’t have the answers to these questions but examining the operational use of this alert even, at its small scale of use, provides opportunities to begin to tease out the danger of a dichotomy between effectiveness and panic and to explore issues around privacy, fear, reliability and usefulness.
In conclusion, this post has provided two different innovations within emergency management, one being experimented with and one which has been implemented. But what is clear is that changes in how we engage with control centres and emergency services are taking place, albeit slowly. But, one can only hope, especially in relation to the alert system, that lobbied criticisms will be engaged with and solutions sought.
Bibliography
911bot (2016) 911bot. [Online]. Available at: http://www.911bot.online/) (Accessed 9th November 2016).
Beck, U., (1992). Risk Society: Towards a New Modernity. London: Sage.
Beck, U., (2009). World of Risk. Cambridge: Polity Press.
Fiegerman, S.(2016) The story behind the Smartphone Terror Alert in NYC. [Online]. Available at: http://money.cnn.com/2016/09/19/technology/chelsea-explosion-emergency-alert/ (Accessed 9th November 2016).
Infomate (2015) The International Smartphone Mobility Report [Online]. Available for download at: the International Smartphone Mobility Report (Accessed 7th November 2016).
Russell, D. (2015) We just don’t speak anymore. But we’re ‘talking’ more than ever. [Online]. Available at: http://attentiv.com/we-dont-speak/ (Accessed 9th November 2016).
Shropshire, C. (2015) Americans prefer texting to talking, report says. Chicago Tribune [Online]. Available at: http://www.chicagotribune.com/business/ct-americans-texting-00327-biz-20150326-story.html (Accessed 9th November 2016).
Westlake, A. (2016) Finally, there’s a chat bot for calling 911. [Online]. Available at: http://www.slashgear.com/finally-theres-a-chat-bot-for-calling-911-08439211/ (Accessed 7th November 2016).
The event will bring technologists, legal practitioners, technology companies and academics together in order to address the common issues faced by the different parties. The goal is to facilitate the communication of differing perspectives in an effort to formulate a unified approach to developing privacy issues.
Confirmed speakers for the event are:
Keynotes Dara Murphy, TD – Minister for European Affairs and Data Protection. Helen Dixon – Data Protection Commissioner of Ireland.
Confirmed speakers for the first session of the event, “Privacy in a digital world: notions and understandings of privacy in a digital infrastructure”, are:
We are delighted to welcome Rami Albatal and Cathal Gurrin to Maynooth on Wednesday 27th May at 4pm, Iontas Building room 2.31 for the third of our Programmable City seminars this semester. Dr. Rami Albatal is the lead postdoctoral researcher of the Lifelogging team at Insight Centre for Data Analytics at Dublin City University, and received his Ph.D. in Computer Vision in 2010 from Grenoble University, France. His research focuses on three main areas: Lifelogging, Computer Vision and Machine Learning. Currently he is working on new generation of Quantified-Self technologies that employ contextual data gathering and analytics, in the goal of building advanced data-driven decision-making, planning and recommendation platforms. Cathal Gurrin is a lecturer at the School of Computing, at Dublin City University, Ireland and he is an investigator at the Insight Centre for Data Analytics where he leads a research group of 10 people. He is also a visiting scientist at the University of Tromso, Norway. His research interest is personal analytics and lifelogging (a search engine for the self). He has gathered a digital memory since 2006 (including over 15 million wearable camera images) and hundreds of millions of other sensor readings. He is the founder of the world’s first dedicated lifelog meetup group.
The session will introduce the topic lifelogging, explore the current state-of-the-art technology and look forward to a future in which lifelog archives may become commonplace. The current approaches to semantic enrichment will be explored, along with applications and user interfaces. In an era of personal data, Facebook, Twitter, digital photos and many other activities all leave significant trails of personal data. One aspect of personal data gathering that is receiving increasing attention is the concept of lifelogging. Lifelogging is concerned with utilising sensors to create a large archives of personal data, or a surrogate memory for the individual. Applying semantic enrichment and organisational software over this data results in the creation of a lifelog for the individual. Lifelogging has been described as an inevitability and is expected to change life experience for all. Finally, lifelogging raises many societal issues, among them privacy and data security, which will be explored and solutions proposed. This session should be of interest to a wide range of academics and interested parties.






{kind=link}