In May 2014 Ubisoft released a new computer game called Watch Dogs. Having sold over 4 million copies in the first week of sales it is tipped to be the game of the year. In the game, Chicago City is controlled by a central operating system (ctOS). The super computer gets a panoptic view of the city using data from cameras and sensor networks. The information obtained is used to manage the city’s infrastructure and technology as well as to maintain a database of personal information about citizens and their activities. In Watch Dogs, a disgruntled computer hacker finds a way to access and hack the ctOS, allowing him to hijack traffic lights, the power grid, bridges and toll gates, rupture water pipes, disable surveillance cameras and access personal information about fellow citizens. The motive for causing mayhem in the city is to find a gang who were involved in his sister’s death and ultimately take down the corrupt system that runs ctOS. In this article, we take a look at some of the real dangers facing today’s cities from malicious hackers.
A Character Accesses City Infrastructure and Data in Watch Dogs
In terms of technology, Chicago, as presented in Watch Dogs is a smart city. Data is fed into the central operating system and the infrastructure of the city adapts and responds accordingly. Although much of the game is fictional, Watch Dogs draws on existing technologies and echoes what is happening today. For example, Rio de Janeiro has a large control centre which applies data analytics to social media, sensors and surveillance cameras in an attempt to predict and control events taking place in the city. Its mission is to provide a safe environment for citizens. Other cities such as Santander and Singapore have invested in sensor networks to record a range of environmental and traffic conditions at locations across the cities. Earlier this year, Intel and Dublin City Council announced that Dublin is also to get a sensor network for measuring city processes. At present many of these projects are focusing on the technical challenge of configuring hardware, designing standards and collecting, storing and processing data from the city-wide sensor networks. Projects are using the data for a range of services to control the city such traffic management (guiding motorist to empty parking spaces), energy management (dimming street lights if no one is present) and water conservation (using sensors to determine when city parks need water).
The Internet of Things & Security
The roll out of such smart city technology is enabled through the Internet of Things (IoT) which is essentially a network of objects which communicate and transfer data without requiring human-to-human or human-to-computer interaction. The IoT can range from a pace maker sending patient information to a physician, to a fridge informing its owner that the milk is low. In the smart city, sensors automatically relay data to a control centre where it is analysed and acted upon.
The Control Centre in Rio de Janeiro
While Watch Dogs raises important moral and ethical issues concerning privacy and the development of a big brother society via smart city technologies, it also raises some interesting questions about the security and reliability of the technology. In Watch Dogs, the main character can control the city infrastructure using a smart phone due to a security weakness in the ctOS. In reality, we have recently seen objects in the IoT being compromised due to weaknesses in the hardware security. Baby monitoring webcams which were accessed by hackers and demonstrations of how insulin pumps can be compromised are cases which have received media attention. Major vulnerabilities of the IoT, were seen in late 2013 and early 2014 when an orchestrated cyber attack saw 100,000 ‘things’ connected to the Internet hacked and used to send malicious spam emails. The hacked ‘things’ included smart TVs, fridges and media centres. Basic security misconfigurations and failures to alter default passwords left devices open to attack.
Even mature internet technologies such as those used in ecommerce websites are vulnerable to hacking. In May this year e-bay’s web servers were hacked leading to the loss of user data. Security flaws with the OpenSSL cryptography standard (used to transmit data securely on the Internet) came to light in April 2014 with the ‘Heartbleed’ bug. A vulnerability enabled hackers to access the short term memory of servers to capture information such as passwords or credit card details of users who recently interacted with the server. All technologies which can send and receive data are vulnerable to attack and misuse unless strict security protocols are used and kept up-to-date. Unfortunately, as the examples here highlight, it seems that the solutions to security issues are only provided after a problem or a breech has been detected. This is because it’s often an unknown bug in the code or poor coding practice which provides a way for hackers to access systems remotely. There is a reluctance to invest in thorough testing of technologies for such weaknesses. Development companies seem prepared to risk cyber attacks rather than invest in the resources required to identify problem areas.
Hacking the Smart City
The fact that all systems connected to the Internet appear vulnerable to cyber attacks is very worrying when considered in the context of smart cities. Unlike personal webcams, TVs and fridges, the technology of smart cities forms part of a complex and critical infrastructure which is used to calibrate and control a city.While governments and city authorities are generally slow to publicise attacks on their technological infrastructure, the Israeli government has acknowledged that essential services that run off sensors, such as water, electricity and banking, have been the target of numerous hacking attacks. For example, in 2013, the traffic management system for a main artery in the port city of Haifa, was hacked, causing major traffic problems that lasted for several hours. Such malicious hijacking of technology is inconvenient for citizens, costs the city financially and could also have fatal consequences. Last year, it was demonstrated that it was relatively easy to hack the traffic light system in New York City. By sending false signals regarding the traffic flow at particular junctions, the algorithm used to control the traffic light sequence could be outsmarted and fooled into thinking that a particular junction was busy and therefore adjust the green time of traffic lights in a particular direction.
City technology is built on legacy systems which have been incrementally updated as technology has changed. Security was often not considered in the original design and only added after. This makes such legacy systems more vulnerable for exploiting. For example, many of the traffic light coordination systems in cities date from the 1980s when the main security threat was physical interference. Another problem with the city technology is the underlying algorithms which can be purely reactive to the data they receive. If false data is supplied then the algorithm may produce undesirable consequences. While the discussion here has focused on sensors embedded in the city, other sources of data, such as social media are open to the same abuse. In March 2014, the twitter account of The Associated Press was hacked and a message reporting of an attack on President Barrack Obama was posted. This led to $136 billion being wiped of the NY stock exchange within seconds. This is an example of humans using bad data to make a bad decision. If the human cognition process is unable to interpret bad data, what hope do pre-programmed computer algorithms have?
As cities continue to roll out technologies aimed at enhancing the lives of citizens, they are moving towards data driven forms of governance both for long term and short term actions. Whatever type of sensor is collecting data, there is a danger that data can be biased, corrupt, played, contained errors or even be faked through hacking. It is therefore imperative for city officials to question the trustworthiness of data used in decision making. From a technical point of view, the data can be made safe by calibrating the sensors regularly and validating their readings against other sensors. From a security perspective, the hardware needs to be secured, maintained and updated to prevent malicious hacking of the device. Recognising the threat which has been highlighted by Watch Dogs, the US Centre for Internet Security (CIS) issued a Cyber Alertregarding the game stating that ‘CIS believes it is likely that a small percentage of Watch Dog players will experiment with compromising computers and electronic systems outside of game play, and this activity will likely affect SLTT (State, Local, Tribal and Territorial) government systems and Department of Transportation (DOT) systems in particular.’
In other domains, such as the motor industry there is a move to transfer functions from the human operator to algorithms. For example, automatic braking, parking assistance, distance based cruise control and pedestrian detection are becoming mainstream in-car technologies in a slow move towards vehicles which drive themselves. It is likely that managing the city will follow the same pattern and incrementally the city will ‘drive’ itself and could ultimately be completely controlled by data-driven algorithms which react to a network of sensors. Although agencies such as the CIS give some advice to minimise the risk of Cyber Attacks on cities, it seems that hacking of the smart city infrastructure is inevitable. The reliance of cities on software and the risks associated with this strategy are well known (Dodge & Kitchin, 2004; Kitchin, 2014). The problem is compounded by the disappearance of the analogue alternative to smart city technologies (Townsend, 2013). This could lead to prolonged recovery from attacks and bugs due to the total reliance on technology to run cities. Cities therefore need to consider the security risks connected to deploying and using sensors to control a city and make decisions. It is also essential that control loops and contingency plans are in place to allow a city to function during a data outage just as contingency plans are made for handling the loss of other essential services such as power and water.
References
Dodge, M., & Kitchin, R. (2004). Flying through code/space: The real virtuality of air travel. Environment and Planning A, 36(2), 195–211.
Townsend, A. (2013). Smart cities: Big data, civic hackers, and the quest for a new utopia. New York: W.W. Norton & Co.
You can write down equations that predict what people will do. That’s the huge change. So I have been running the big data conversation … It’s about the fact that you can now understand customers, employees, how we organise, in a quantitative, predictive way for the first time.
Predictive analytics is fervently discussed in the business world, if not fully taken up, and increasingly by public services, governments or medical practices to exploit the value hidden in the public archive or even in social media. In New York for example, there is a geek squad to Mayor’s office, seeking to uncover deep and detailed relationships between the people living there and the government, and at the same time realising “how insanely complicated this city is”. In there, an intriguing question remains as to the effectiveness of predictive analytics, the extent to which it can support and facilitate urban life and the consequences to the cities that are immersed in a deep sea of data, predictions and humans.
Let’s start with an Australian example. The Commonwealth Scientific and Industrial Research Organisation (CSIRO) has partnered with Queensland Health, Griffith University and Queensland University of Technology and developed the Patient Admission Prediction Tool (PAPT) to estimate the presentations of schoolies, leavers of Australian high schools going on week-long holidays after final examines, to nearby hospitals. The PAPT derives their estimates from Queensland Health data on schoolies presentations in previous years, including statistics about the numbers of presentations, parts of the body injured and types of these injuries. Using the data, the PAPT benefits hospitals, their employees and patients by improved scheduling of hospital beds, procedures and staff, with the potential of saving $23 million per annum if implemented in hospitals across Australia. As characterised by Dr James Lind, one of the benefits of adapting predictive analytics is the proactive rather than reactive approaches towards planning and management:
People like working in a system that is proactive rather than reactive. When we are expecting a patient load everyone knows what their jobs [are], and you are more efficient with your time.
The patients are happy too, because they receive and finish treatment quickly:
Can we find such success when predictive analytics is practised in various forms of urban governance? Moving the discussion back to US cities again and using policing as an example. Policing work is shifting from reactive to proactive in many cities, in experimental or implementation stages. PredPol is predictive policing software produced by a startup company and has caught considerable amount of attention from various police departments in the US and other parts of the world. Their success as a business, however, is partly to do with by their “energetic” marketing strategies, contractual obligations of referring the startup company to other law enforcement agencies, and so on.
Above all, claims of success shown by the company are difficult to sustain in closer examination. The subjects of the analytics that the software focuses are very specific: burglaries, robberies, vehicle thefts, thefts from vehicles and gun crimes. In other words, the crimes that have “plenty of data to chew on” for making predictions, and are of the opportunistic crimes which are easier to prevent by the presence of the patrolling police (more details here).
This further brings us to the issue of the “proven” and “continued” aspects of success. These are even more difficult and problematic aspects of policing work for the purpose of evaluating and “effectiveness” and “success” of predictive policing. To prove that an algorithm performs well, expectations for which an algorithm is built and tweaked have to be specified, not only for those who build the algorithm, but also for people who will be entangled in the experiments in intended and unintended ways. In this sense, transparency and objectivity related to predictive policing are important. Without acknowledging, considering and evaluating how both the crimes and everyday life, or both normality and abnormality, are transformed into algorithms and disclosing them for validation and consultation, a system of computational criminal justice can turn into, if not witchhunting, alchemy – let’s put two or more elements into a magical pot, stir them and see what happens! This is further complicated by knowing that there are already existing and inherent inequalities in crime data, such as reporting or sentencing, and the perceived neutrality of algorithms can well justify cognitive biases that are well documented in justice system, biases that could justify the rational that someone should be treated more harshly because the person is already on the black list, without reconsidering how the person gets onto such list in the first place. There is an even darker side of predictive policing when mundane social activities are constantly treated as crime data when using social network analysis to profile and incriminate groups and grouping of individuals. This is also a more dynamic and contested field of play considering that while crime prediction practitioners (coders, private companies, government agencies and so on) appropriate personal data and private social media messages for purposes they are not intended for, criminals (or activists for that matter) play with social media, if not yet prediction results obtained by the reverse engineering of algorithms, to plan coups, protests, attacks, etc.
For those who want to look further into how predictive policing is set up, proven, run and evaluated, there are ways of opening up the black box, at least partially, for critically reflecting upon what exactly it could achieve and how the “success” is managed both in computer simulation and in police practices. The Chief scientist of PredPol gave a lecturer where, as pointed out:
He discusses the mathematics/statistics behind the algorithm and, at one point, invites the audience not to take his word for it’s accuracy because he is employed by PredPol, but to take the equations discussed and plug in crime data (e.g. Chicago’s open source crime data) to see if the model has any accuracy.
The video of the lecturer is here
Furthermore, RAND provides a review of predictive policing methods and practices across many US cities. The report can be found here and analyses the advantages gained by various crime prediction methods as well as their limitations. Predictive policing as shown in the report is far from a crystal ball, and has various levels of complexity to run and implement, mathematically, computationally and organisationally. Predictions can range from crime mapping to predicting crime hotspots when given certain spatiotemporal characteristics of crimes (see a taxonomy in p. 19). As far as prediction are concerned, they are good as long as crimes in the future look similar to the ones in the past – their types, temporality and geographic prevalence, if the data is good, which is a big if!. Also, predictions are good when they are further contextualised. Compared with predicting crimes without any help (not even from the intelligence that agents in the field can gather), applying mathematics to help in a guessing game creates a significant advantage, but the differences among these methods are not as dramatic. Therefore, one of the crucial messages intended by reviewing and contextualising predictive methods is that:
It is important to bear in mind that the predictive methods discussed here do not predict where and when the next crime will be committed. Rather, they predict the relative level of risk that a crime will be associated with a particular time and place. The assumption is always that the past is prologue; predictions are made based on the analysis of past data. If the criminal adapts quickly to police interventions, then only data from the recent past will be useful to police departments. (p. 55)
Therefore, however automated, human and organisational efforts are still required in many areas in practice. Activities such as finding relevant data, preparing them for analysis, tweaking factors, variables and parameters, all require human efforts, collaboration as a team and transforming decisions into actions for reducing crimes at organisational levels. Similarly, human and organisational efforts are again needed when types and patterns of crimes are changing, targeted crimes shift, results are to be interpreted and integrated in relation to changing availabilities of resources.
Furthermore, the report reviews the issues of privacy, transparency, trust and civil liberties within existing legal and policy frameworks. However, it becomes apparent that predictions and predictive analytics need careful and mindful designs, responding to emerging ethical, legal and social issues (ELSI) when the impacts of predictive policing occur at individual and organisational levels, affecting the day-to-day life of residents, communities and frontline officers. While it is important to maintain and revisit existing legal requirements and frameworks, it is also important to respond to emerging information and data practices, and notions of “obscurity by design” and “prodecural data due processes” are ways of rethinking and designing relationships between privacy, data, algorithms and predictions. Even the term transparency needs further reflections to make progress on issues concerning what it means under the context of predictive analytics and how it can be achieved by taking into account renewed theoretical, ethical, practical and legal considerations. Under this context, “transparent predictions” is proposed wherein the importance and potential unintended consequences are outlined with regards to rendering prediction processes interpretable to humans and driven by causations rather than correlations. Critical reflections on such a proposal are useful, for example this two part series – (1)(2), further contextualising transparency both in prediction precesses and case-specific situations.
Additionally, IBM has partnered with New York Fire Department and Lisbon Fire Brigade. The main goal is to use predictive analytics to make smart cities safer by using the predictions to better and more effectively allocate emergency response resources. Similarly, crowd behaviours have already been simulated for understanding and predicting how people would react in various crowd events in places such as major traffic and travel terminals, sports and concert venues, shopping malls and streets, busy traffic areas, etc. Simulation tools take into account data generated by sensors, as well as quantified embodied actions, such as walking speeds, body sizes or disabilities, and it is not difficult to imagine that more data and analysis could take advantage of social media data where sentiments and psychological aspects are expected to refine simulation results (a review of simulation tools).
To bring the discussion to a pause, data, algorithms and predictions are quickly turning not only cities but also many other places into testbeds, as long as there are sensors (human and nonhuman) and the Internet. Data will become available and different kinds of tests can then be run to verify ideas and hypotheses. As many articles have pointed out, data and algorithms are flawed, revealling and reinforcing unequal parts and aspects of cities and city lives. Tests and experiments, such as manipulating user emtions by Facebook in their experiments, can make cities vulnerable too, when they are run without regards to embodied and emotionally chared humans. Therefore, there is a great deal more to say about data, algorithms and experiments, because the production of data and experiments of making use of them are always an intervention rather than evaluation. We will be coming back to these topics in subsequent posts.
This afternoon’s black cab blockade of London comes in response to car ride apps that are changing the character of the city’s taxi industry. While there has been little visible backlash against comparable services in Ireland, it seems only a matter of time before these struggles find their way to our shores.
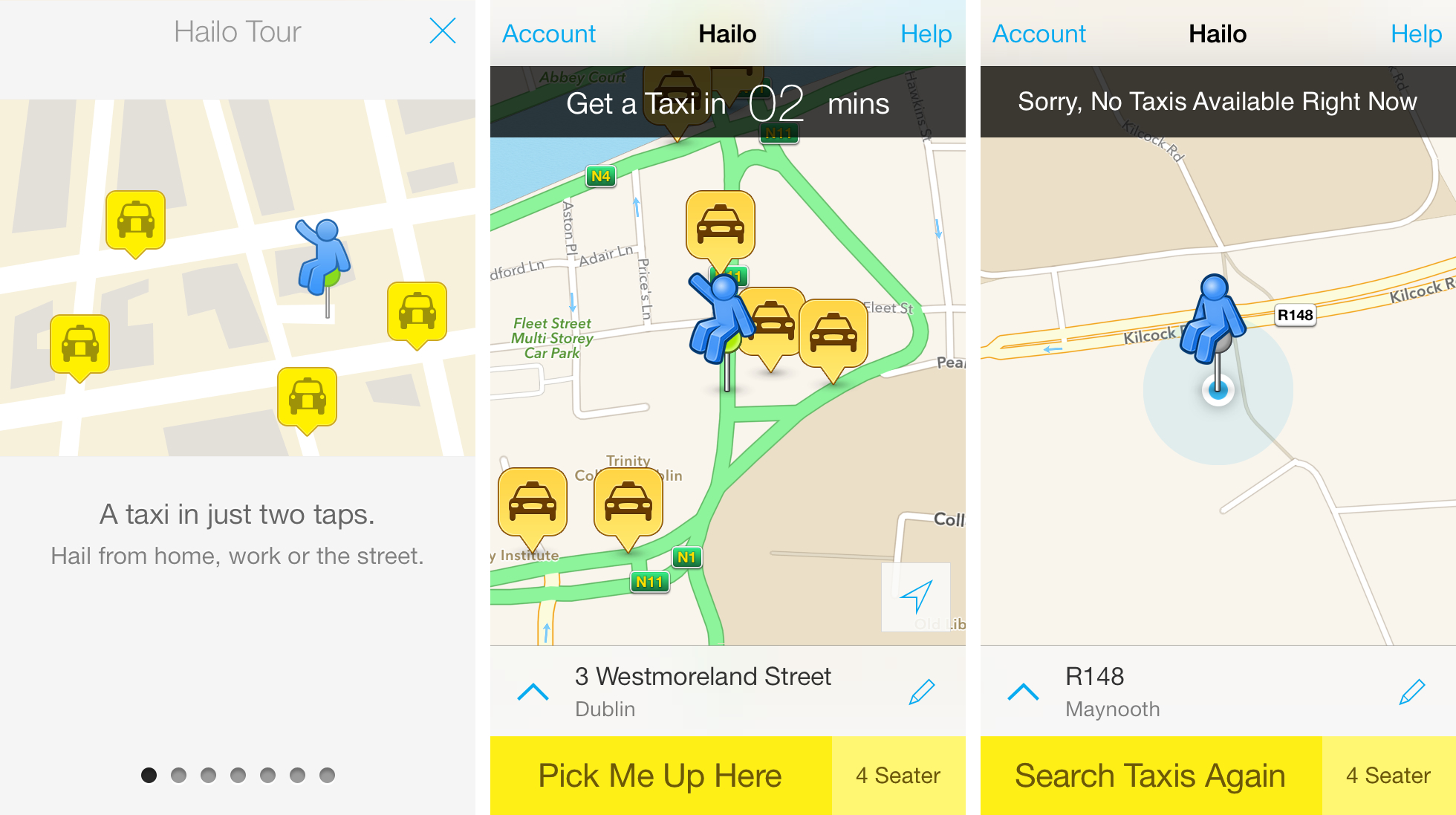
The market-leading smart phone taxi service in Ireland is Hailo. Self-described as “the evolution of the hail”, Hailo was founded in November 2011 by three London taxi drivers and three entrepreneurs. It launched in Dublin, its second city, in July 2012 and as of mid-2014, provides sporadic coverage across the country with a specific attention on areas of high population density.
To use Hailo as a potential passenger, one needs simply to download and launch their free smart phone application. To use the Hailo as a driver, things are a little more complicated. One must sign up using a geographically specific online portal (such as exists for London, Ireland, New York, Boston and Tokyo). Registration is restricted to licensed taxi drivers such that Hailo is effectively leveraging the screening procedures of existing small public service vehicle (SPSV) infrastructure in Ireland. Of Dublin’s 12,000 registered taxi drivers, I’ve been told that about half are using the service.
In this post I will describe two observations on the role Hailo plays in Dublin: that it competes with existing taxi infrastructure, and that it capitalises on and potentially extends the deregulation of transportation in the city. I will briefly compare the service to Uber and Lyft, and argue why their competition will likely bring the taxi wars to Dublin.
Hailo competes with existing taxi infrastructure
In addition to plying for hire (being in motion and available for hire) and standing for hire (being stationary and available for hire), taxi drivers can increase their number of fares by enrolling to a radio service. When a customer phones a taxi company, this company then leverages its radio-enabled network to source an available taxi driver. Cab drivers working in Dublin have told me that subscription to such a service can cost as much as €5,000 per year. This service is dependent upon a radio communications unit being physically installed into driver’s vehicle, the hire of which is presumably incorporated into the cost of the service.
Hailo, in drawing upon already existing smart phone usage, does not need to install any radio communications infrastructure. This means lower fixed capital costs and lower associated installation and maintenance costs. Furthermore, by having software perform the role of the radio operator, there are presumably fewer attendant labour costs.
These factors lead to a considerably different pricing model. Rather than charge a yearly subscription fee, Hailo is free to install and use, but charges a 12% commission on every fare sourced through the application. In order to compete with these rates, a €5,000 per year radio service would need to direct €41,667 worth of fares to each driver. Understandably, Hailo poses a considerable threat to Dublin’s taxi radio companies.
There is however an important geographical caveat which needs to be made. In cities such as Dublin – where there is a confluence of high population density, a high number of taxis per head and a high usage of smart phones – the benefits of Hailo to both drivers and passengers outweigh those offered by taxi radio companies. In a geographical location where taxi or smart phone use is more sparsely distributed however, Hailo has less opportunity to draw upon existing infrastructure. Where I work in Maynooth – a small university town 20 kilometres west of Dublin – it is very difficult to find a taxi using Hailo. In such locations both spatial scarcity and community loyalty lead me to suppose far less competition between Hailo and existing taxi radio services. In these instances, the volume of jobs rather than rate of commission is the important factor.
Competing SPSV smart phone service Uber, which has been recently valued at a truly astounding $18.2bn1, launched in Dublin in January 2014. Uber operates under a business model which is far more challenging to existing taxi infrastructures as a whole. Rather than recruit taxi drivers exclusively, Uber is open to private hire vehicle (or limousine) drivers as well. Less regulation on the cost of limousine services allows the company to employ a surge pricing model, so that fares can cost considerably more than a standard rate (up to as much as eight times more expensive in rare incidences of peak demand). The cost of an SPSV licence for limousines in Ireland is only €250, compared to the €6,300 for a taxi licence. While cars must still be deemed as fit for such a purpose, and drivers must similarly undergo clearance by An Garda Síochána, Uber hopes that its matchmaking infrastructure for limousine services will allow its service to compete favourably with the taxi industry as a whole. It’s probably too soon to draw any conclusions on the success of the company in Dublin, but you can be sure they are here for the long run. Uber have money to burn and their CEO Travis Kalanick has a combative attitude toward vested interests.
Hailo capitalises on and potentially extends the deregulation of transportation in the city
As described above Hailo is most effective in urban areas where there is already considerable competition amongst taxi drivers. Uptake amongst drivers is dependent upon a pull effect, whereby not using the service would render them excluded from a proportion of the passenger market. There is, as such, a supply-and-demand-like positive feedback loop between the driver and passenger applications. Increased use of the application by one group would be expected to result in an increase in use by the other.
It was not always so easy to hail a taxi in Dublin. Between 1978 and 2000 local authorities in Ireland were entitled to limit the number of taxi licences issued in their area. In Dublin, the number of licences in circulation between 1978 and 1988 was fixed at 1,800. This number was increased slowly through the late 1980s and 1990s to around 2,800 by the end of the decade. Supply was not kept up with demand however. By the late 1990s the cost of purchasing a licence on the open market was as much as €100,000. In line with its commitment to improving Dublin’s taxi services, the Action Programme for the Millennium encouraged the issuance of 3,100 new licences in the city in November 1999. This was not found to be enough however, as one year later, on November 21, 2000, S.I No. 367/20002 lifted licensing regulations in Ireland. This had the immediate effect of devaluing existing licences and subsequent enquiries and legal cases have been undertaken to assess the fairness of this deregulation. The change has had its intended effect however. By 2008, union estimates placed the number of taxi licences nationwide at 19,000 with 12,000 of those being held in Dublin. Locals tell me that these days it is much easier to get a cab home after a night out than it was in the 1990s.
Under conditions where taxi drivers do not have to compete so vigorously for fares (under a licence-restricted, consortium-based or heavily unionised model rather than the predominantly individualised system currently in operation in Ireland), there would be little pressure for them to use Hailo. And as I’ve already argued, no drivers using the service would translate to no passengers using it either. Indeed it is quite clear from various interviews and media appearances that Hailo have made tactical decisions about how and in which cities they introduce their service.
While Hailo takes advantage of such spaces of deregulation, it has been careful so far to adhere to local legislation. The service does not on its own necessitate a further deregulation of the SPSV sector in Ireland. Hailo is not unique however. Competitors include the globe-spanning Uber, Lyft, Sidecar, Wingz, Summon and Flywheel in the USA, cab:app, Cab4Now, Get Taxi and Kabbee in London and Chauffeur-Privé in France. These transportation network companies compete on a range of business models, services and geographical coverage. This marketplace of competing car ride apps has the potential to push against regulations which are in place to control regional SPSV sectors in Ireland.
Consider the following examples from what’s been called the taxi wars.
Since March 2014, Republican Senator Marco Rubio has been pushing for the deregulation of the limousine industry in Miami, Florida specifically to make way for the introduction of Uber. The taxi and limousine industry in Miami-Dade county is strongly regulated. The industry caters to a population of over 2,500,000 people through 2,121 taxi medallions (which is the equivalence of a vehicle licence in Ireland). This has forced the market price of a medallion to around $340,000, 28% of which are owned by taxi drivers. Similarly, limousines licences are limited to 625 in number. Services must be booked an hour in advance with rides costing a minimum of $70. This regulation is directly restrictive of Uber’s business model. After Senator Rubio’s efforts to clear the company’s way stalled, actor Ashton Kutcher was recruited to tackle regulation from a different front, decrying the city’s bizarre, old, antiquated legislation” on Jimmy Kimmel Live. On May 22 rival company Lyft – “your friend with a car”, which adopts a decentralised ride sharing model – launched in Miami on a donation-based payment scheme. This forced a response by Uber, which launched its comparably modelled UberX service in the city on June 4. These are not isolated events. Similar changes are being forced on other regions of the US such as: Arlington, Virginia; San Antonio, California; and Austin, Texas.
Uber arrived in London, it’s first European city, in mid-2012. London’s taxi industry consists of over 25,000 hackney carriage taxis serving a daytime population of around 10,000,000. In order to obtain a taxi licence, or Green Badge, drivers must pass to a knowledge test covering a 113 square mile area of the city which is purported to require up to five years of study. Uber, in accepting any driver with a private hire vehicle licence, poses a clear threat to the time and money that London’s taxi drivers have invested in their profession. In recent weeks, The Licensed Taxi Drivers Association has summoned six Uber drivers to court, alleging that the Uber smartphone app is equivalent to a taximeter and therefore illegal under the 1998 Private Hire Act which reserves that right for licensed taxi drivers. In addition, the London taxi-driver’s union lambast Transport for London for failing to pursue the illegal activities which Uber facilitate, suggesting that the state body is afraid of the money backing Uber. In response, Transport for London has sought a binding decision from the high court regarding the legality of the smart phone taximeter.
The way in which other transportation network companies have responded to Uber’s entrance into the London market is important in the case of Ireland. Hailo have announced that they will extend their services to private hire vehicles in addition to taxis. This was news was not well accepted by the industry, with the word ‘scabs’ being gratified on the wall of Hailo’s London office. The company responded on their website, insisting that they are simply following consumer demand. Assuming the move doesn’t too badly damage its position among existing service users, we can expect to see something similar in Ireland, either to pre-empt or combat Uber’s growing market share. Not all apps are going the way of private vehicle hire however. Competitor Cab:app has pushed back against the trend set by Uber and Hailo, asserting publicly its commitment to the taxi industry.
Protests in London and throughout Europe today (June 11, 2014) are in direct opposition to Uber’s perceived infringement upon the taxi industry. In the past, strike action has escalated to involve the destruction of property. In January 2014, Parisian taxi drivers struck in opposition to Uber’s unregulated market competition. Confrontations between unionised taxi drivers and Uber drivers resulted in “Smashed windows, tires, vandalized vehicle[s], and bleeding hands”.
The Irish SPSV sector is admittedly quite different from comparable industries in America, the UK and France. Hailo does not face the same kind of regulatory barriers in Ireland as it would in parts of the US. The National Taxi Drivers’ Union is less powerful than taxi unions in London, and certainly less militant than those in Paris. Hailo is a relatively well behaved company in this sector however. As competitors such as Uber and Lyft seek to expand their more aggressive strategies throughout Europe, it is highly likely, given the success of Hailo and Dublin’s reputation as a high-tech-friendly city, that a real push will be made to establish a foothold in Ireland. Spokesperson for Uber’s international operations Anthony El-Khoury has told the Irish Times: “We see a lot of potential in the Irish market and a lot of demand”. As this market heats up, pressure to further deregulate the SPSV industry will be put on Dublin City Council and the Irish government.
The future of the SPSV sector in Ireland
These two preliminary observations on the role of Hailo in Dublin are commensurate with larger tendencies of state deregulation and market-oriented competition. While the emergence of car ride apps may be positioned as a form of Schumpeterian creative-destruction, there are larger political and economic forces within which these applications should be contextualised. I have attempted to sketch some of these forces in this blog post.
The taxi industry is regulated for a reason. The screening and approval of drivers is important in ensuring accountability and the safety of passengers. Regular metering and Ireland’s nationwide fare system (which was instituted in September 2006) make certain that taxis provide an honest and consistent service that does not gouge rural communities or those in need. While Hailo operates under a minimally challenging model to these standards, it does not exist in a vacuum. By exploiting the freer regulation of limousines, Uber is effectively side-stepping many but not all of them. By doing away with accreditation altogether, Lyft would throw these standards onto the wills of the market. Car ride apps have the potential to put huge pressure on the taxi and limousine business. If other European cities are anything to go by Ireland’s SPSV sector is likely to be forced to deregulate further in coming years. This impacts the price, availability and safety of taxi services, and undercuts the ability of workers in the industry to bargain for fair pay and work conditions. It is important that any changes to the sector be submitted to proper public scrutiny and debate.
June 12 – An article on RTE alerted me to the recent launch of Wundercar in Dublin. The app seems to follow the Lyft or UberX business model, whereby unlicensed drivers give passengers a lift somewhere in the city for “tips”. Drivers are screened by Wundercar rather than An Garda Síochána.
June 22 – The Independent reported on June 20 that Hailo is offering a suite of new services targeting the business sector. Most significant to my discussion here is the introduction of the company’s limousine option to Ireland. Limousine licences are considerably cheaper than taxi licences and there are fewer regulations on fare pricing.
While there I was struck by the number of times maps were displayed. The mapping of public policy issues related to openness seems to have become a normalized communication method to show how countries fare according to a number of indicators that aim to measure how transparent, prone to corruption, engagemed civil society is, or how open in terms of data, open in terms of information, and open in terms of government nation states are.
What the maps show is how jurisdictionally bound up policy, law and regulatory matters concerning data are. The maps reveal how techno-political processes are sociospatial practices and how these sociospatial matters are delineated by territorial boundaries. What is less obvious, are the narratives about how the particularities of the spatial relations within these territories shape how the same policies, laws and regulation are differentially enacted.
Below are 10 world maps which depict a wide range of indicators and sub-indicators, indices, scorecards, and standards. Some simply show if a country is a member of an institution or is a signatory to an international agreement. Most are interactive except for one, they all provide links to reports and methodologies, some more extensive than others. Some of the maps are a call to action; others are created to solicit input from the crowd, while most are created to demonstrate how countries fare against each other according to their schemes. One map is a discovery map to a large number of indicators found in an indicator portal while another shows the breadth of civil society participation. These maps are created in a variety of customized systems while three rely on third party platforms such as Google Maps or Open Street Maps. They are published by a variety of organizations such as transnational institutions, well resourced think tanks or civil society organizations.
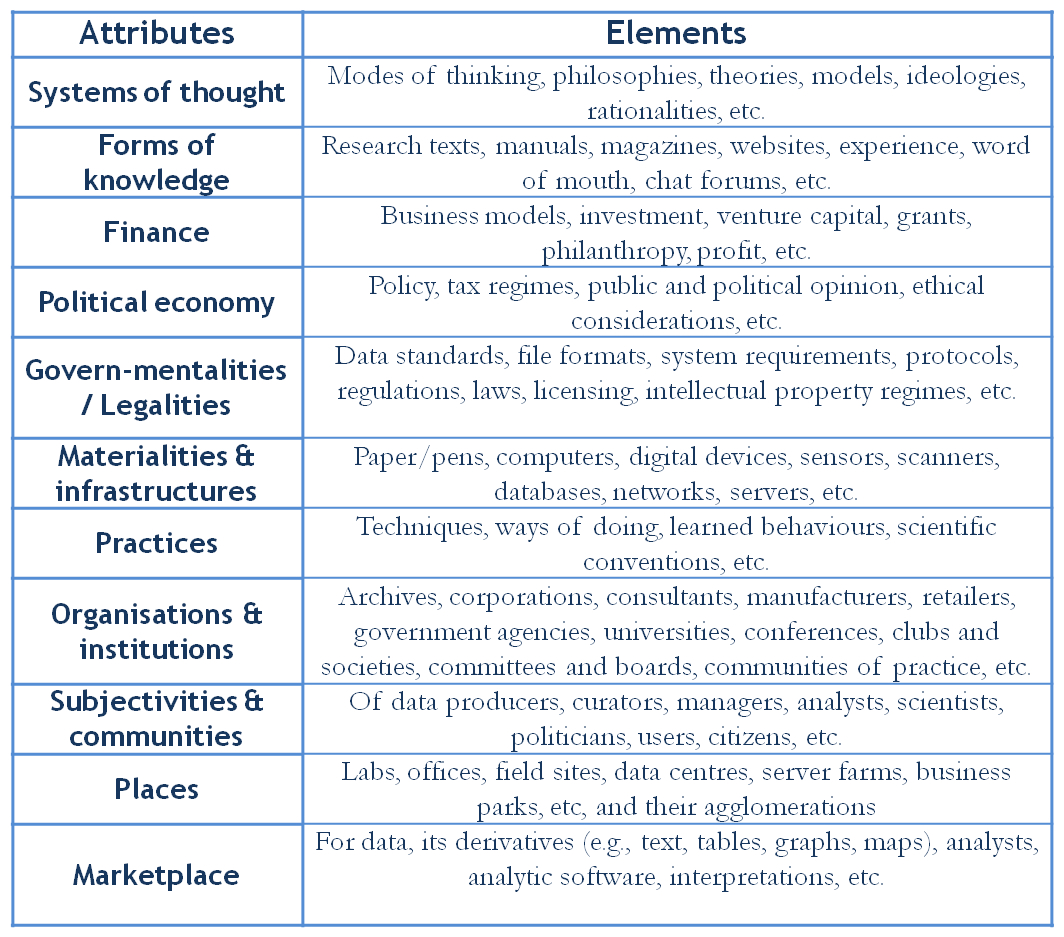
We do not know the impact these maps have on the minds of the decision makers for whom they are aimed, but I do know that these are often shown as backdrops to discussions at international meetings such as the OGP to make a point about who is and is not in an open and transparent club. They are therefore political tools, used to do discursive work. They do not simply represent the open data landscape, but actively help (re)produce it. As such, they demand further scrutiny as to the data assemblage surrounding them (amalgams of systems of thought, forms of knowledge, finance, political economies, governmentalities and legalities, materialities and infrastructures, practices, organisations and institutions, subjectivities and communities, places, and marketplaces), the instrumental rationality underpinning them, and the power/knowledge exercised through them.
This is work that we are presently conducting on the Programmable City project, which will complement a critical study concerning city data, indicators, benchmarking and dashboards, and we’ll return to them in future blog posts.
Users land on a blank blue world map of countries delineated by a thick white line, from which they select a country of interest. Once selected a series of indicators and indices such as the ‘Corruption measurement tools’, ‘Measuring transparency’ and ‘Other governance and development indicators’ appear. These are measured according rankings to a given n, scored as a percentage and whether or not the country is a signatory to a convention and if it is enforced. The numbers are derived from national statistics and surveys. The indicators are:
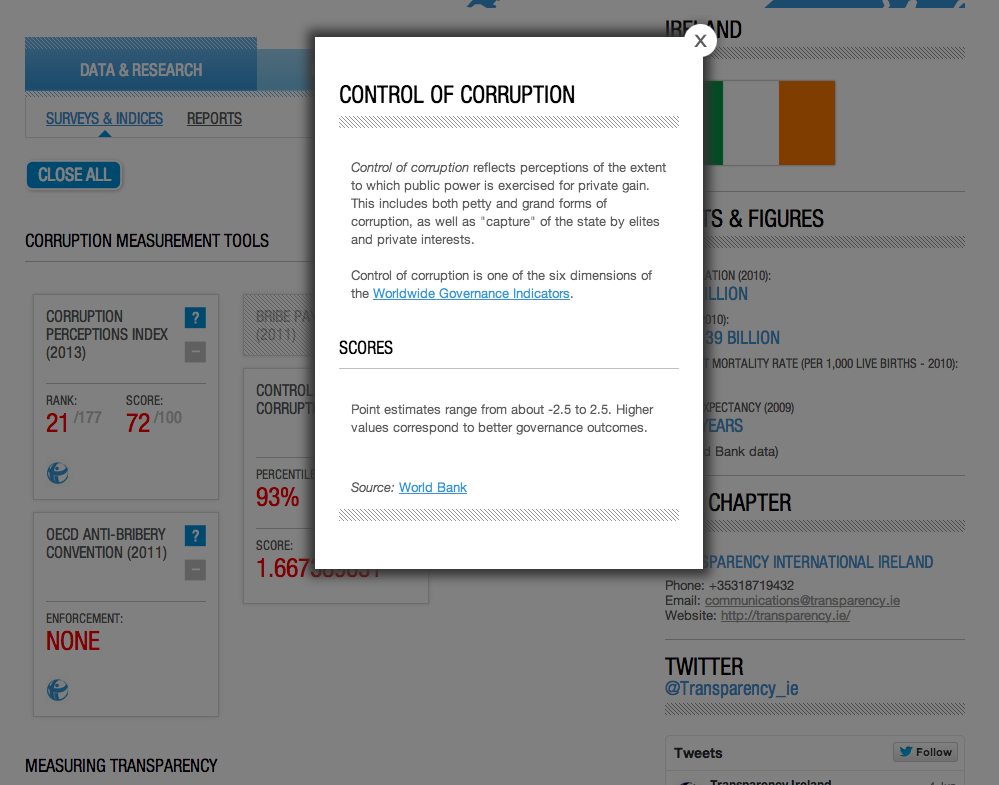
Corruption Perceptions Index (2013), Transparency International
Control of Corruption (2010), World Bank dimension of Worldwide Governance Indicators
The Bribe Payer’s Index (2011), Transparency International
Global Corruption Barometer (2013), Transparency International
OECD Anti-Bribery Convention (2011)
Financial Secrecy Index (2011), Tax Justice Network
Open Budget Index (2010), International Budget Partnership
Global Competitiveness Index (2012-2013), World Economic Forum Global Competitiveness Index
Judicial Independence (2011-2012), World Economic Forum Global Competitiveness Index
Human Development Index (2011), United Nations
Rule of Law (2010), World Bank dimension of Worldwide Governance Indicators
Press Freedom Index (2011-2012) Reporters Without Borders
Voice & Accountability (2010), World Bank dimension of Worldwide Governance Indicators
By clicking on the question mark beside the indicators, a pop up window with some basic metadata appears. The window describes what is being measured and points to its source.
The page includes links to related reports, and a comments section where numerous and colourful opinions are provided!
Users land on a Google Map API mashup of Government, Citizen and Private Open Government initiatives. They are given the option to zoom in to see local initiatives. In this case, users are led to a typology of initiatives which define what Open Government means from civil society’s point of view.
Initiatives are classified with respect to the following categories 1) Transparency, 2) Participation and 3) Accountability. The development of the Open Government Standards are being coordinated by “Access Info Europe, a human rights organisation dedicated to the promotion and protection of the right of access to information in Europe and the defence of civil liberties and human rights with the aim of facilitating public participation in the decision-making process and demanding responsibility from governments”.
Definitions, parameters and criteria for a number of sub-indicators are being crowsourced in the online forms like the following for Openness:
The following is a list of standards that are a currently under development.
This is an interactive Open Street Map (OSM) Mapbox map depicting the locations where there is Global Integrity fieldwork national reports arranged by the year these were published. Reports are called Country Assessments and each includes: a qualitative Reporter’s Notebook and a quantitative Integrity Indicators scorecard.
The Integrity Indicators scorecard assesses “the existence, effectiveness, and citizen access to key governance and anti-corruption mechanisms through more than 300 actionable indicators. They are scored by a lead in-country researcher and blindly reviewed by a panel of peer reviewers, a mix of other in-country experts as well as outside experts. Reporter’s Notebooks are reported and written by in-country journalists and blindly reviewed by the same peer review panel”.
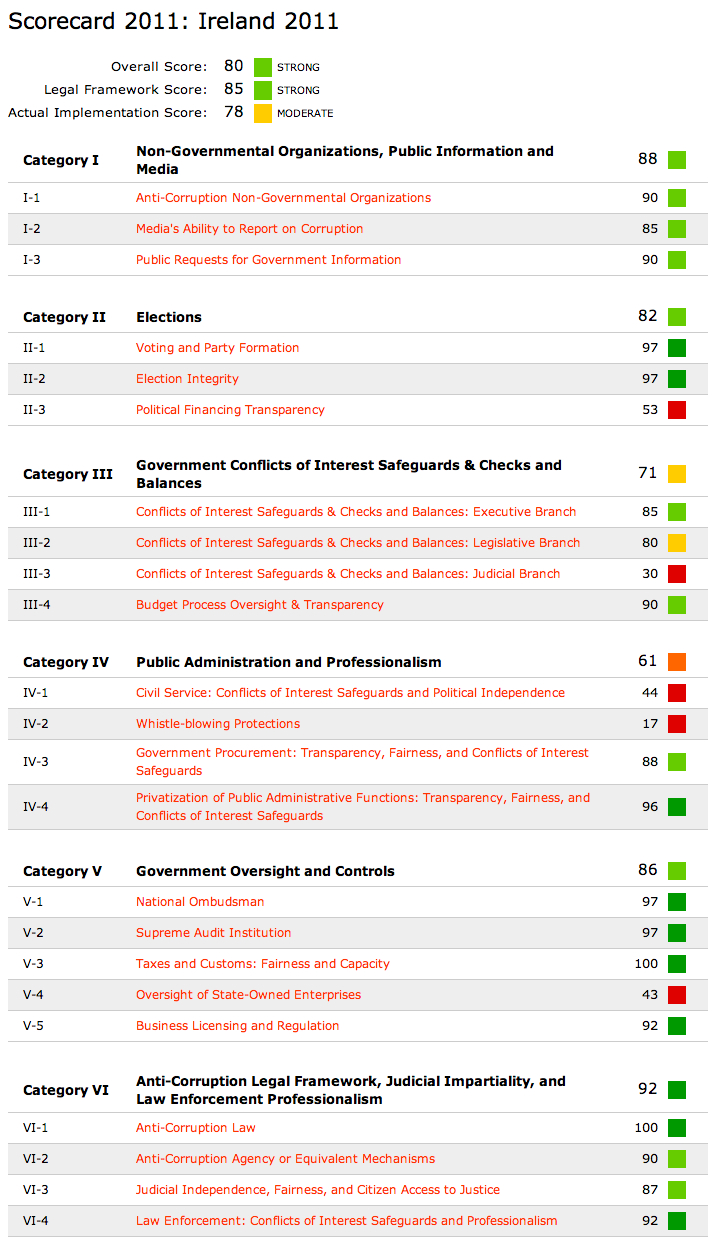
Users select a country, and below the map a number of scorecard indicators appear. Scorecard indicators are arranged into 6 major categories:
Non-Governmental Organizations, Public Information and Media
Elections
Government Conflicts of Interest Safeguards & Checks and Balances
Public Administration and Professionalism
Government Oversight and Controls
Anti-Corruption Legal Framework, Judicial Impartiality, and Law Enforcement Professionalism
Users can then access how each score was derived by following sub-category links. Below is an example of legislation and the score associated with the Political Financing Transparency indicator which is a sub-class of the Elections category.
PDF copies of the reports are also available, as are spreadsheets of the data used to derive them.
This is an interactive map depicting the World Bank’s Global Integrity Index, which is one of its Actionable Governance Indicators (AGIs). AGIs “focus on specific and narrowly-defined aspects of governance, rather than broad dimensions. These indicators are clearly defined, providing information on the discrete elements of governance reforms, often capturing data on the “missing middle” in the outcome chain”. The map allows users to select from a drop down menu which includes a subset of AGI indicator – the portal contains thousands. The interactive and downloadable map aims to graphically demonstrate the progress of governance reform worldwide. The map is but a small picture of what the Portal contains and below is a Governance At A Glance country report for Ireland.
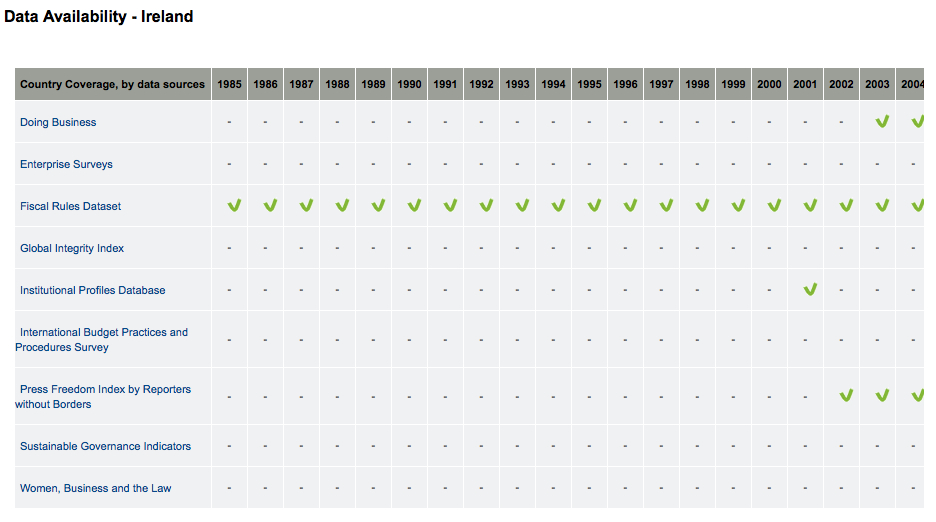
And here is a data availability table, also for Ireland.
The interactive map depicts the countries that have signed onto the Open Government Partnership and in which cohort they belong. Users can select their country of choice which hyperlinks to that country’s membership status and its progress to date in meeting the criteria for membership, where it ranks in terms of commitment and links to related documents such as action plans and progress reports. It is interesting to note, that the Independent Review Mechanism reports are not included in this list. Canada’s IRM report was submitted in 2014.
The Open Data Barometer map depicts the 77 countries the Open Data Institute has evaluated. This map assesses how open data policies are implemented in these countries according to three main indicators:
Readiness of:
government,
citizens and civil society and
entrepreneurs and business,
Implementation based on the availability a variety of datasets within the following sub-categories:
accountability
social policy
Innovation
The following Emerging Impacts :
Political
Social
Economic
These are also graphically depicted in a radar chart, as well as a bubble chart where the size of the bubble represents the availability of the datasets per category and if these sets meet the Open Definition Criteria. The data and associated methodologies are explained in the website about the report.
This is a static map depicting where Open Contracting Support and Tools are implemented. Sadly, the 5 indicators depicted on the map were not explained or described. I would have to contact them at a later time to find out!
This map is depicting the findings of the World Freedom Index Report for 2014, with a particular focus on how countries rose and fell from the previous year. 180 Countries are scored against the following criteria which are based partly on a questionnaire, violence committed against journalists the algorithm of which is clearly defined in the PDF copy of the report. Data and the report are fully downloadable, and more detailed maps with a legend are provided in the report itself and a methodology report.
This is an interactive map that depicts the pledges made by nationally elected political officials to the European Parliament and asking them to commit to “stand-up for citizens and democracy against the excessive lobbying influence of banks and big business in the EU?” Mousing over a country triggers a pop-up menu which lists which party has made a commitment, while clicking on the map directs users to the page below which is a tool whereby citizens can fill in a form letter and have it sent to their elected officials to solicit them to pledge.
This is a partially curated and partially crowsourced map on the OGP Civil Society Hub Website. The starred drops represent countries that are official OGP members, while the red drops represent any number of civil society organizations that have in some way engaged with the OGP, some of which are transnational while others are national or sub-national entities. Once a location is selected, a pop-up menu appears that includes a national flag, a link to that nation state’s official OGP member site, and provides users with the option to pick from who is involved, a selection of topic areas or a list of information resources. The map is a means to find people and activities and also a means by which to have people self identify and be recognized as civil society actors but also to connect people.
Introduction to a series of blog posts on big data:
By Tracey P. Lauriault, Programable City Project.
My area of research on the Programmable City Project examines how digital data materially and discursively support and process cities and their citizens. This work falls within an emerging field called critical data studies. A recent working paper entitled Small Data, Data Infrastructures and Big Data, is an example of critically thinking about data, as is the forthcoming book The Data Revolution: Big Data, Open Data, Data Infrastructures and Their Consequences and my earlier work on data preservation, access, and data infrastructures. The new Big Data and Society journal also provides some theoretical orientation. Dublin and Boston, are the Programmable City’s formal study sites and I will add a little bit of Canada in that mix from time to time.
The first part of my research consists of constructing ‘data landscapes’ for Dublin and Boston, by which I mean mapping out the different organisations involved in producing, analyzing, and selling data and analytic services, of which big data are an important component. A key element is reading a number of reports, papers, and consultations on the topic, as well as conducting interviews and attending industry and academic events, I will share questions and observations here in blog posts. At first, these will mainly be descriptive and comparative. However, this reading combined with empirical case studies will lead to a more critical examination of the data assemblages of big data, open data, indicators, maps and data infrastructures. I will be guided by two theoretical frameworks, Rob Kitchin’s ‘Data Assemblages’ and a modified Ian Hacking Making Up People and Spaces framework.
The report was commissioned “to advance recommendations on measures to build up the big data and analytics talent pool through domestic graduate output, continuing professional development within industry, and, where necessary, attraction of talent from abroad including expatriate talent”. The Government’s ambition is for the Republic to become a leading country in the field of big data in Europe, and the report is designed to guide the creation of an Irish big data ecosystem based on public and private collaboration.
The research for this study was driven by the Joint Industry/Government task force on Big Data which was formed in June 2013. Big data is also considered to be a disruptive reform in the Action Plan for Jobs 2013, which is a reform considered to have the“potential to have a significant impact on job creation, to support enterprises or where Ireland can profit from a natural advantage or opportunity that presents itself in the economy” and a research priority Data Analytics, Management, Security and Privacy 2013. Forfas commissioned the research in a Request for Tender for the Provision of Research for the Study Assessing the Demand for Big Data / Data Analytics Skills in Ireland 2013-2020 (LINK TO PDF) in July 2013.
Ernst & Young (E & Y) and Oxford Economics were jointly commissioned to blend their different fields of expertise to conduct the international trend analysis, undertake the consultations with companies and key informants and to model big data and analytics skills demand scenarios. Their work was overseen by a 17 member Steering Group chaired by the EGFSN.
The Big Data Skills Report was overseen by a Joint Industry/Government task force on Big Data and a Steering Group with representation primarily from the private sector (IBM, Accenture, Glanbia, CPL, Datahug, Nanthean Technologies, Deloitte, Vidiro Analytics, Enterprise Ireland, IDA Ireland and the Quinn School of Business) and 4 government offices (Revenue Commissioners, Department of Education and Skills, Higher Education Authority and Forfás).
Provenance:
The report is the outcome of a number of fast tracked high level strategies for the Government of Ireland as follows:
The Department of Jobs, Enterprise and Innovation (DJEI) considers big data to be Priority Area B in the Research Prioritization Steering Group (Mar. 2012) report after Priority Area A which is Future Networks and Communications.
This is followed by the DJEI’s Action Plan for Jobs 2013 (Feb. 2013) that repositions big data as Disruptive Reform 1 which is to “Build on our existing enterprise strengths to make Ireland a leading country in Europe in ‘Big Data’”.
Meanwhile outside of government SAS UK and Ireland commissions the Centre for Economics and Business Research (Cebr) to assess the big data sector and releases Data equity – Ireland Unlocking the value of big data (June 2013) coining the term ‘data equity’ from the idea of brand equity. Companies will be forming data equity with the power of analytics.
Big data is then considered to be a Global Technology and Service Trends Influencing Irish ICT Skills Demand in the Forfas Expert Group on Future Skill Needs (EGFSN) report Addressing Future Demand for High-Level ICT Skills.(Nov. 2013).
As part of the actions plan, Forfas launches a Request for Tender for The Provision of Research for the Study Assessing the Demand for Big Data / Data Analytics Skills in Ireland 2013-2020 which was awarded to E & Y and Oxford Economics.
Big data is positioned again as disruptive and integrated with ICT skills, it is a “disruptive growth and innovation phase. This includes the adoption of cloud computing, the penetration of mobile devices and technologies and the Internet of things, the emergence of Big Data analytics, IT security, micro- and nanoelectronics and the adoption of social technologies in both the personal and business environment” in the EGFSN ICT Skills Action Plan (Mar. 2014) also an outcome of the Action Plan for Jobs 2013.
How are big data analytical skills categorized in the Big Data Skills Report?
The objectives of the Report were to forecast the future annual demand across the economy between 2013 – 2020, for big data & data analytics and related roles which included a mapping of qualifications, skillsets and competency requirements. Skill categorization was pre-determined in the Request for Tender as follows:
1. Deep Analytical Talent skills requiring a combination of
advanced statistical, analytical, and machine learning skills,
business skills to assess the meaning of data and to derive business insights &
communications skills to explain/persuade other executives.
These roles can originate from a range of backgrounds such as mathematicians, statisticians, actuaries, operational research analysts, economists and include the newly termed role of the ‘data scientist’.
2. Big Data Savvy; comprising of “data savvy”
managers,
CIO’s,
market research analysts,
business and functional managers.
These professionals require an understanding of the value and use of big data & data analytics to enable them to interpret and utilise the insights from the data and take appropriate decisions to advance their company strategy and drive business performance.
3. Supporting technology roles; these personnel have the skills to develop, implement and maintain the hardware and software tools required to make use of Big Data/Data Analytics software and hardware. The core technologies of those implementing Big Data solutions tend to be focused Hadoop and a growing range of SQL databases. These roles include:
programmers and software development professionals and
IT business analysts, architects & system designers.
These 3 categories were originally created by the McKinsey Global Institute (MGI) in their 2011 Big data: The next frontier for innovation, competition, and productivity report. The original MGI categorization is as follows. Note that these categories are restricted to the mention of ‘hard skills’ types of occupations. Therefore big data is considered to be primarily a technical field.
Role Categories and Occupation Types (p.38)
E & Y expanded the MGI categorization in the Big Data Skills Report as seen in the skills, competences and qualifications requirements in the table below. In this case, under the ‘Big Data and Analytics Savvy’ category, some public policy, regulatory and governance roles ‘hard skills’ such as data protection and IP Knowledge are taken into consideration, while Ethics is considered to be a ‘soft skill’ for both ‘Deep Analytical Talent’ and ‘Big Data Savvy’.
Types of Skills and Competencies Required Across Categories (p.50).
This is the last we see of these types of ‘soft’ and ‘hard’ skills in the report. Which is rather unfortunate, as leadership and innovation in any field requires good governance, and this is especially the case for big data. Furthermore, once a categorization gets amplified, institutionalized and authorized it becomes real and begins to ‘make up kinds of people’ as per Ian Hacking’s framework and as illustrated below in Lauriault’s Making up People and Places framework based on Hacking’s work. Classifications describe people and places, institutions begin to use that class, it becomes part of expert knowledge, in this case MGI, E & Y and Oxford Economics. Once set, experts begin to count, quantify, normalize and correlate things, in this case skills, academic qualifications, and employment data. Once these are reported, an institution or groups of experts take some action, in this case they develop a strategy and some action plans. Once actions are taken, the class really becomes true, scientific or real as it becomes a thing. It becomes a normal part of doing business, a part of a bureaucratic process, in this case, where public sector moneys will be directed toward increasing a set of skills to meet a demand determined by the data analytics private sector in Ireland. In terms of resistance, it may be, that with time we will see those labelled as part of the ‘Deep Analytical Talent’ pool may want to be called data scientists, the ‘Big Data Savvy’ group may want to be big data governors while the supporting Technology Group may want to be considered as big data infrastructure providers.
In this case the DJEI in its Request for Tender has firmed up these categories by making them the focus of the research, and these have now become real categories in the Republic by E & Y and Oxford Economics who structured their analysis accordingly. It is expected that these will appear in many future analyses.
Expert knowledge informing the skills demand model in the Big Data Skills Report:
The development of baseline estimates and projections for big data employment in Ireland were informed by the following reports:
In addition, the Big Data Skills Report adopts the most common definition of big data developed by Gartner in 2001, namely a field that works with datasets that are big in volume, velocity and variety, or the 3Vs. The definitions of big data have however evolved and below is a comparative table developed by Kitchin (2014). The Big Data Skills Report does not however discuss data.
huge in volume, consisting of terrabytes or petabytes of data;
high in velocity, being created in or near real-time;
diverse in variety, being structured and unstructured in nature, and often temporally and spatially referenced;
exhaustive in scope, striving to capture entire populations or systems (n=all) within a given domain such as a nation state or a platform such as Twitter users, or at least much larger sample sizes than would be employed in traditional, small data studies;
fine-grained in resolution, aiming to be as detailed as possible, and uniquely indexical in identification;
relational in nature, containing common fields that enable the conjoining of different data sets;
flexible, holding the traits of extensionality (can add new fields easily) and scalability (can expand in size rapidly).
(Boyd and Crawford 2012; Dodge and Kitchin 2005; Marz and Warren 2012; Mayer-
Schonberger and Cukier 2013).
The definition of big data, the Big Data Skills Report, skills demand models, skill categories, resulting scenarios and recommendations were all authored and created by private sector entities. Concurrently, the Steering Group overseeing this study mostly represents private sector interests. And the direction of the strategy falls under the Joint Industry/Government task force on Big Data. It can then be concluded that those who stand the most to gain from the recommendations made in the report also authored and oversaw them. In other words, there is no critical assessment of the findings, and it would seem that no one is looking out for the public interest.
A more objective approach would have included broader membership of the Steering Group and the EGFSN by including academic experts from the social sciences, information studies, communications or media studies, members of legal and financial professions, ethicists, public sector big data producers or independent think tanks. Also, what if the process was overseen by the ‘Joint Industry/Government Public Interest task force on Big Data’? Had that been the case, there may have been a focus on some of the more pernicious effects of big data & data analytics, such as privacy, procurement, security and ethics. It would have been preferable to first have a national big data research and development strategy for the Republic of Ireland with a focus on how big data can help resolve national issues (e.g., environment, housing, financial, energy, agriculture), identify where expertise in those areas lies or is lacking, and then direct resources toward the resolution of those. In addition, a national strategy would have included an inventory of all the private sector entities involved in big data on the Island and a survey of the skills sets in house and sought to develop a skills demand baseline from that, combined with an inventory of skills in the public and academic sectors. Finally, an analysis of the public policy issues related to big data, including threats to the public interest would have been assessed, and along with a big data private sector, R & D strategy, there would have been a big data governance process in place that would include a regulatory framework and some checks and balances to guide the sector toward ethical conduct.
What did the Big Data Skills Report do?
1. The drivers for a big data were defined.
Big data is a disruptive reform in the Action Plan for Jobs 2013 related to a growing industrial sector and subsequently job growth in the country, big data is also considered to be a sector from which significant value can be derived and therefore worth investing in. Interestingly, open government and open data are considered as drivers. This is unusual since most data found in open data portals are characterized as small data. It is true that that the public sector and publicly funded research produce and analyze datasets that would be characterized as big data, but these have been being produced for quite some time, are quire specialized and have been disseminated under a PSI Licence prior to the advent of open data. Open data as a driver may be attributed to the fact that the private sector can better commercialize public sector data, both big and small, by combining these with theirs or using public sector data as a baseline. All sectors stand to gain if public sector data are coordinated, centrally discoverable, well described in metadata, free and under an open licence.
The new Post Code system to be deployed in Ireland by 2015 was considered to be a “late mover adoption” in the Report. Paradoxically, this will not be an open data framework dataset available to the public as it is being produced and licenced under a cost recovery program. The “Postcode Management Licence Holder” (PMLH) contract is to Capita Business Support Services Ireland (supported by BearingPoint and Autoaddress) and the PMLH contract will be fulfilled by the Capita-owned business, Eircode. The new post code will be particularly helpful to big data companies, marketers and direct mailing companies wishing to compete with the postal service, but will not necessarily be useful for civil society organizations as it will be too costly. The average citizen may also be paying for these data multiple times:
the public paid for the creation of the dataset in the first place,
it will become a cost included in the price of products,
as part of taxation because government agencies will have to acquire these under a cost recovery regime (e.g., each local authority, all national departments, and etc.)
tuition fees as academic institutions will also have to pay for this dataset.
There are a number of other important framework datasets not mentioned in the report, most notably the small area file produced by the National Centre for Geocomputation at NUIM developed for the CSO. This allowed for the first time, in the 2011 census, fine grained analysis of neighbourhoods in Ireland and would be of benefit to the big data sector as data big and small need to be aggregated into common and small geographies. Along with open data, and framework datasets, the report did not discuss the formation of a spatial data infrastructure which is how many other nations deal with national and sub-national geospatial datasets such as road network files, small area files, post code files, demographic base files, environmental and natural resources data to name a few. SDIs are the means by which datasets of this nature, are standardized, made interoperable and accessible. This would also be of assistance to big data interests, but also for social, economic and environmental management for the country. These are more robust than open data initiatives as they are based on interoperable policies, standards and technologies that are adopted enterprise wide. The Canadian Geospatial Data Infrastructure for instance is now becoming a platform and open data will be integrated into it while departments will be geo-enabling their administrative datasets accordingly.
2. Baseline employment demand was determined
The MGI, Accenture, Cebr and SAS reports mentioned earlier informed the skills demand model. The following explains how it was done:
E & Y and Oxford Economics determined that reports consistently estimated that existing employment in this sector consisted of 1.5% to 2% of total employment, although categorizations differed.
Eurostat data were used to compare shares of employment in Ireland and the UK by sector and CSO Data from the Quarterly National Household Survey (QNHS) were used (See figure 3.2 p. 42).
Based on estimates and proportions for the US and UK, the Deep Analytical Talent employment demand for Ireland was estimated.
Also, the proportion of those in established roles was considered to be more than half of that demand while the remainder are emerging analytical roles.
The Big Data Savvy demand was determined by applying the proportion of total employment in this category in the US to the Irish employment data.
The Supporting Technology demand was derived from structured interviews with the 45 enterprises and organizations in Ireland. A ratio of 1:4 was determined of Deep Analytical Talent to Supporting Technology professionals.
To understand the sectoral distribution, the analysis in the 2011 MGI report was used. In the MGI analysis low, medium and high data intensity based on data storage capital stock per firm groups were devised. CSO data were used here to “understand the data intensity of industries as the capital stock in computer software per employee” (p.44).
Below is the table of the Results:
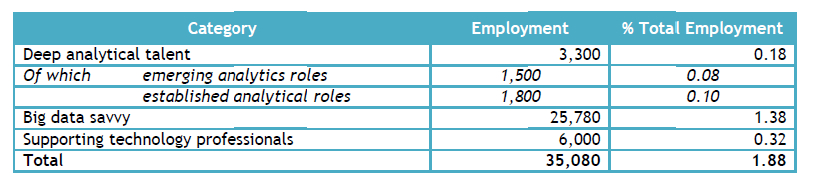
Estimate of Baseline Demand in Big Data and Analytics in Ireland (p.45).
The above was the extent of the methodological information provided explaining how baseline demand numbers were derived. No metadata, tabular data or dates were provided, nor details about which CSO and Eurostat data were used, nor was there any anayslis provided on how the classes were adjusted to the 3 categories of skills defined in this Big Data Skills Report. Ireland is not that big a country and a survey of all the companies doing big data analytical work could have yielded a much more robust baseline. Estimates of growth were based on the UK and the US. The assumption that the composition of the firms here differs as a result of the favourable tax regime and that Ireland is a much smaller country suggest that those estimates would be an overstatement for Ireland.
3. Structured consultations were conducted
A Structured Interview Survey about the employment levels across each of the three categories was conducted by telephone with 45 Forfás selected Irish based enterprises and organisations that employ big data & data analytics talent. This included 35 companies (foreign owned and indigenous), 7 government bodies, 2 data analytic research centres and 10 key informants. Some workshops were also held.
Demographics, vacancies, the difficulty in filling vacancies were determined. In addition future demands, predicted growth, the difficulty in acquiring and keeping talent, sources of future skills, where sources of skill could be sought within the most common disciplines, training opportunities, relationships with academia, turnover, and attrition were estimated. The results of which are presented in the Information box below (p. 59).
In lots of ways this part of the report left more questions than answers. Which companies and institutions were surveyed? How many companies do this type of work in Ireland? What were the questions asked in the survey? How were vacancies and the difficulty to fill positions determined? Did companies classify the skill sets they needed in the same way that MGI, E & Y and Oxford Economics did? If not how were differences rectified? As discussed, the big data categories and classifications did not focus on public policy issues which resulted in the social sciences and law faculties being unmentioned in the lists of university programs, and most notably absent from the report are the pools of both ‘Deep Analytical Talent’ and ‘Big Data Savvy’ skills found in geodemographics, geocomputation, geomatics, geophysics as well as the earth sciences. While humanities is mentioned in the report, the digital humanities was not.
This section, like the previous lacked a methodological explanation and the bread crumbs required to assess results. The focus is heavily oriented toward the hard skills, and the recommendations are generally quite sensible. However, of concern is the recommendation that “third level, cooperation between industry and academia is crucial to ensure that education reflects skills needs. Proposals included involving industry experts in devising curricula and teaching analytics on university programs” (p.59). This is problematic as universities could simply become instruments to serve corporate interests, and in order to cut costs research may become too instrumentally focussed into a particular sector at the expense of others, and in both cases this may thwart critical reflection in this area for fear of budget losses. Finally there is a concern that this may also lead to an overemphasis on quantitative research and undermine programming in other areas such as qualitative research, and the social sciences.
4. Big data future demand scenarios were produced
Three scenarios were offered which included expansion, replacement and skills demand projections as well as up-skilling demand. These were derived by examining the growth projections and demand baselines discussed earlier, the information collected during the consultations and E & Y and Oxford Economics domestic economy sectoral employment forecasts.
The scenarios factored in the following global drivers for big data:
Increase in the creation and availability of data
Growing recognition of economic returns from the use of big data
A few global risks were described, none of which included privacy, security, intellectual property, procurement and ethics, although the fact that along with a lack of relevant data there may also be an abundance of high quality data.
The scenarios for Ireland were based on a number of assumptions, drivers and supporting conditions as seen in the table below:
Summary of Scenario Assumptions, Drivers and Supporting Conditions (p.71)
Resulting in the following predictions as seen in the table below. Scenario 3 would Position Ireland as the leading country in Europe in big data, Scenario 2 would be the forecast if Ireland caught up to other countries such as the UK, while Scenario 1 represents low growth.
Summary of Future Demand Change Projections, 2013-2020 (p.82)
It is difficult to say if any of these projections are reasonable as there are no supporting data, data sources, cross classification mapping or algorithms provided. Furthermore, these scenarios are also based on the problematic baseline demand numbers discussed earlier. The implications of Scenario 3 are however enormous. Should Scenario 3 be adopted, significant investment in education and training in quantitative and computational areas would be required in universities, potentially at the expense of non-quantitative fields, such as those related to governance and public interest issues discussed earlier, some fields would be overlooked while inducements would be required to keep existing and new talent here. The drivers for Scenario 3 are in play, and the outcomes are entirely focussed on private sector big data R & D, and not directed at applying big data resources toward addressing issues of national importance such as environment, energy, quality of life, housing or climate change. If my observations are correct, the strategy is for public sector funding to be directed toward the alleviation of the shortage in skills in this sector, for R & D to answer questions developed by the private sector (INSIGHT and CeADAR), and for inducements to keep skilled personnel here, while also continuing to support a favourable tax regime and FDI inducements. Some Irish citizens may benefit from some of the new jobs that may come on offer, but how Irish Society benefits as a whole and what is in the general public interest in any of these scenarios is uncertain.
5. The big data skills supply was determined
The MGI 2001 and the Cebr 2013 reports informed the model used to determine the current supply of big data skills. MGI conducted an analysis of US education data in fields renowned for having advanced quantitative training. Ratios were derived of the total graduates and then applied internationally. It is only here do we find the physical sciences and social sciences listed. The Cebr report considers supply and demand but its analysis factored in a different set of academic programs where the physical and social sciences, are not factored in. The analysis in Ireland examined a series of courses and programs considered most relevant to the production of the Deep Analytical Talent cohort such as:
Dedicated big data & analytics programmes
Programmes that include significant training/elements in data analytics
Maths, Statistics and Science
Engineering programmes
Physics programmes
Data analytics programmes in Northern Ireland
Private data analytics programmes
Online education in data analytics
This part of the report was more comprehensive as the types of programs, courses and numbers were provided in the analysis and it was estimated that approximately 2000 graduates per year in courses most directly related to emerging deep analytics. Again, graduates related to the ‘Big Data Savvy’ governance and law types of programs were not focussed on, this is a missed opportunity for Ireland and a very large oversight of this report.
6. Policy measures here and abroad were examined
Policy was defined loosely to encompass a range of methods to grow the skills supply discussed throughout. A list of international measures to grow talent was discussed, such as post secondary program measures, but also collaboration between industry and higher education institutions that might entail the following:
Offering ‘real world’ work problems and large datasets to mine;
Providing data analytics software and hardware;
Providing relevant work experience opportunities;
Shaping specialisms or electives within programmes (including the actual provision of the taught modules);and
Promoting analytics as a career path for students.
These are relatively straight forward approaches, but I would add the cautionary note of ensuring that students should be able to study on multiple platforms and there should be no exclusive deals or monopolies on platforms and software; that work experience be tied with some sort of fair remuneration, that there be the allowance for critical analysis. The offering of real world data sets from the private sector would also be most exciting. Because of a lack of focus on big data governance issues, no recommendations in this area were made.
There are also many other initiatives already in place in Ireland which form part of the Action Plans for Jobs report. Significant investment in research institutes such as INSIGHT which partners with industry to address private sector problems within a number of important themes such a health, economy, journalism and humanities, energy and the environment, sport and wellness, telecom & network and media processing. There is also R & D investment into CeADAR which is another major research institute that partners with the private sector to deliver quantitative and computational skills. There has also been investment in infrastructure such as the Irish Centre for High-End Computing and the Telecommunications Software and Systems Group.
7. Recommendations in the Big Data Skills Report
Many of the recommendations in the report were previously commented on. Chapter 8 provides a number of tables with short, medium and long term suggestions. There were however a number of items scattered in this chapter that are new and notable:
“The overarching recommendation is that a consultative group comprising representatives of industry, academia and relevant agencies should be established” to oversee the implementation of recommendations over a 6 month period.
This is refreshing, and it is hoped here that more than just business school and technical fields from academia will be reflected in the composition of this consultative group and that there will be room for critical debate.
“For Ireland to become a leading country for big data a higher level of skills supply will also be required. This will involve and enhanced supply of Masters and PhD graduates along with an expansion of places on courses designed for those in advance degrees in STEM to transition into high-end analytics.”
“Introduce targeted competitive funding available for post graduate specialist analytics programmes to reduce tuition fees, incentivise participation and increase places available.”
Beyond what was previously mentioned earlier in terms the focus on ‘hard skills’, there is currently a hiring cap in universities in Ireland, a wage cap, and a devaluation of the ‘soft skills’ required to develop the governance and legal issues related to a growing big data industry in Ireland. Careful consideration here is required to ensure that the non STEM departments do not suffer losses in order to build up the ‘hard skills’ demand, and that a set of ‘soft skills’ be developed. The following are some notable examples in other jurisdictions: The Centre for Law Technology and Society, Canadian Internet Public Policy Interest Clinic, The Munk School of Global Affairs, The Citizen Lab, and The Berkman School for Internet and Society.
“Business communication skills, critical thinking and project management skills should be taught across all STEM disciplines”.
This is a welcome addition. A bonus would be up-skilling ethics, law and public policy departments toward an understanding of big data issues.
“Firms should adopt an enterprise-wide approach to managing their analytical capabilities, including the up-skilling of staff for data protection and governance”.
Beyond up-skilling staff, there needs to be a recognition that this sector needs to be regulated, and a number of public policy issues need to be addressed, which implies that resources toward academic disciplines such as political science, public policy, law, communications, contract law, media studies, and social-sciences.
“…Career guidance in schools should communicate the availability of career opportunities in analytics to students (particularly females) and their parents.”
This is also a refreshing recommendation. Women Invent Tomorrow, Digi Women, Coder Dojo’s and Women in Technology and Science (WITS) in Ireland have done great work in this area, and a number of important studies have been published on the topic. Female STEM experts often complain that they are invited to boy’s schools but not girl’s schools. The Big Data Consultative Group should include experts from these organizations and refer to existing studies to develop this recommendation.
“Industry and State Agencies should work with the CSO and Revenue Commissioners to explore the possibility of further developing official measurements of big data and analytics employment”.
This is very important, and the recommendation I would make is for the creation of an open and comprehensive business register that would include a profile of the skills in all firms, including big data, combined with an open and accessible inventory of all businesses involved in big data in Ireland. The greatest concerns about this report, is the fact that the numbers are based on very loose definitions, combined with the absence of an inventory of what is currently ongoing in Ireland, along with the imposition of categories that may not apply.
The public service recommendations are seen in the table below (p.111):
These are all welcome recommendations, and as discussed making the post code file open should also be a part of this, and this procurement process should be referred to as an example of how to acquire a service not for the public interest. There should also be serious consideration for the creation a national spatial data infrastructure. Companies can help the public sector overcome its data analytical short comings; however this needs to be accompanied by good procurement practices and agreements whereby government own the data and can look under the hood of any software or analytical output provided, and that data be interoperable with multiple analytical platforms and not locked into proprietary systems. In addition, in the science based departments, there is significant data analytical capabilities that have been overlooked here, especially in the EPA, Marine, ordinance survey, the Commissioner for Irish Lights, the CSO, population health and others. Perhaps along with an inventory of data assets an inventory of in house skills and the development of a cross departmental and jurisdictional public sector big data analytical working group should be created.
Finally, the report ends with “the economic and social benefits available from enhanced adoption of big data and analytics are potentially transformative. The spectrum of benefits on offer spans from improved health and environmental outcomes to better efficiency”. This is fantastic; however, the body of the Report did not discuss any targeted efforts at these issues. And it is this along with other issues discussed throughout this analysis that is part of the Report’s major shortcomings.
Final Observations
The report is to be lauded for attempting to address in a relatively tight time frame the criteria as set in the Request for Tender. It sets out a picture of the big data landscape in Ireland, before providing a number of recommendations as to how to nurture and expand Ireland’s role as the international site for big data research and development and commercial enterprise.
The report, however, also has some shortcomings and limitations. It is, for example, narrowly focused on developing strategies to build the human resources capacity for private sector companies in Ireland through the use of public education and research funds, with only a small focus on the private sector funding the training of its own staff. Moreover, the focus is almost exclusively on the ‘hard skills’ in areas of product and service development. In fairness, it is part of a larger Action Plan for Jobs and an outcome of this is the government’s research strategy of Data Analytics, Management, Security and Privacy 2013. Although, management, security and privacy in that strategy are primarily discussed in instrumental and technological terms and not in public policy terms, nor are these discussed in the Big Data Skills Report, most notably there is no mention of law and regulation.
Unfortunately the report was not created to inform and complement a national big data strategy. The strategy therefore is not R & D in general, or for the support of thematic areas that could benefit from big data analytics such as molecular biology, marine research, pharmaceutical and agribusiness, addressing climate change or energy production and efficiency in Ireland. Instead, the strategy is about jobs and skills for existing industry already involved in big data analytics, and to some extent the public sector, and not about a plan for the nation, nor for what might be considered the public good. For example, there is no systematic mapping out of the big data sector in Ireland; there is no inventory of the companies engaged and what they do; there is no analysis of the infrastructure required, albeit there is discussion elsewhere about cloud and high end computing; there is no understanding of the software used; nor do we know if there are clusters of excellence or knowledge where big data analytics are concentrated except for INSIGHT and CeADar which are excellent R & D instrumental programs. There was an excellent investigation on the skills supply side in Chapter 6, although digital humanities, geosciences, geocomputation, geomatics and the earth sciences were left out as major contributors to developing a pool ‘Deep Analytical Talent’.
Furthermore, the report does not include a focus on building public policy capacity related to issues such as law, privacy, data protection, regulation, copyright, procurement, patents, intellectual property (IP) and data resale, to name a few. The creation of public internet interest legal clinics, developing centres of excellence or think tanks in these areas as well as the creation of internet law and policy research chairs would be a good way to complement the demand for ‘hard skills’ focus. These ‘soft skills’, competencies and qualifications are subsumed within the Big Data Savvy category, although there is no explicit mapping of these against what is offered in academic institutions. The solution is envisaged as a hollowing out of the state with the private sector undertaking public sector work: ‘Public sector employers are less ambitious about their future employment levels, in part due to the current restrictions on recruitment. Part of their demand is likely to be addressed through outsourcing to the private sector” (p.13).
The policy implications of government outsourcing data analytical functions to the private sector are troublesome to say the least. Questions of who own the data? Can those data be shared with the public in an open fashion? What was the model used to do the analysis? What algorithms were deployed and are they propriety? There are issues of ownership and control that must be addressed. The Post Code exemplifies these problems, it is a lauded example in the Report, yet this is a significant public sector big data investment will primarily benefit the private sector and not the public. If evidence based decision making is something the Irish Government is truly invested in, and it would seem that it is with its open government and open data strategies, then those legal, policy, methodological, data life-cycle management and procurement issues need to be addressed. This is especially the case if issues of public expenditure and forecasting are based on the output of private sector companies who may stand to gain from the analysis, as is the case of the outcomes of this report. Uncritical predictive governance is also of growing concern, necessitating, along with investment in the ‘hard skills’. Investment in the social sciences and critical thinking are also required, and these skills need to be found in non STEM academic departments. Political economy, communications, media studies, political science, socio-technological studies, public policy and public affairs, should also be part of the big data ecosystem in Ireland. I think this is one of the big missed opportunities of this Report.
If Ireland truly wants to become an innovator in this field and the leading country in the field of big data in Europe then part of that leadership should include law, regulation and policy. These are conspicuously absent and perhaps this is the result of the drivers. It is overseen by a Joint Industry/Government task force on Big Data and a Steering Group with representation primarily from the private sector. The EGFSN also does not include lawyers, auditors, actuaries and public policy experts, but it does include an excellent group of subject matter experts and dedicated public servants in a number of areas. Industry needs to be tempered by solid public policy and regulation, while the public interest needs to be factored into any government strategy, industry is very well represented here, the public interest beyond jobs and FDI is not.
The Report, curiously mentions the Government’s joining of the Open Government Partnership as well as the development of its open data strategy, as these are considered as enablers of big data. This is unusual, as most of the data public administrations produce are small data, and that includes the Census and mapping agencies such as the Ordnance Survey. Making government data easier to find and under less restrictive licencing would make everyone’s job easier, and that is a good thing. Although, a spatial data infrastructure would be better in the long term. In addition, this would allow for greater commercialization of public sector data, as small data, and the big datasets produced by some departments and publicly funded research could be combined with private sector data and also be used to develop baselines. The Report does not discuss small data in a meaningful way except to mention that they exist. The Big Data Skills Report is, overly reliant on the analysis of the McKinsey Global Institute 2011 report entitled Big data: The next frontier for innovation, competition, and productivity, and it is here that open data is mentioned as a driver. This aligns with earlier work on the Programmable City that points to open data increasingly being of interest for commercialization purposes. Opening government is a good thing, as are open data in general, but these are a small part of the big data puzzle, and procurement needs to take an open by design approach, and avoid situations such as the post code and the Ordinance Survey.
The report offers an analysis of existing employment demand, produced three future demand scenarios, assesses Ireland’s skill supply, and makes some useful recommendations and these were discussed in detail earlier on. There are a number of big data strategies found in a number of government reports introduced at the beginning of this post, in addition to this one, but what is sorely missing is an overall strategy that would be of benefit to the Republic, that would tackle issues of importance to Irish society, be in the public interest, while also encouraging and supportive of private sector investment.
For the past few years I’ve co-taught a professional development course for doctoral students on completing a thesis, getting a job, and publishing. The course draws liberally on a book I co-wrote with the late Duncan Fuller entitled, The Academics’ Guide to Publishing. One thing we did not really cover in the book was how to write and place pieces that have impact, rather providing more general advice about getting through the peer review process.
The general careers advice mantra of academia is now ‘publish or perish’. Often what is published and its utility and value can be somewhat overlooked — if a piece got published it is assumed it must have some inherent value. And yet a common observation is that most journal articles seem to be barely read, let alone cited.
Both authors and editors want to publish material that is both read and cited, so what is required to produce work that editors are delighted to accept and readers find so useful that they want to cite in their own work?
A taxonomy of publishing impact
The way I try and explain impact to early career scholars is through a discussion of writing and publishing a paper on airport security (see Figure 1). Written pieces of work, I argue, generally fall into one of four categories, with the impact of the piece rising as one traverses from Level 1 to Level 4.
Figure 1: Levels of research impact
Level 1: the piece is basically empiricist in nature and makes little use of theory. For example, I could write an article that provides a very detailed description of security in an airport and how it works in practice. This might be interesting, but would add little to established knowledge about how airport security works or how to make sense of it. Generally, such papers appear in trade magazines or national level journals and are rarely cited.
Level 2: the paper uses established theory to make sense of a phenomena. For example, I could use Foucault’s theories of disciplining, surveillance and biopolitics to explain how airport security works to create docile bodies that passively submit to enhanced screening measures. Here, I am applying a theoretical frame that might provide a fresh perspective on a phenomena if it has not been previously applied. I am not, however, providing new theoretical or methodological tools but drawing on established ones. As a consequence, the piece has limited utility, essentially constrained to those interested in airport security, and might be accepted in a low-ranking international journal.
Level 3: the paper extends/reworks established theory to make sense of phenomena. For example, I might argue that since the 1970s when Foucault was formulating his ideas there has been a radical shift in the technologies of surveillance from disciplining systems to capture systems that actively reshape behaviour. As such, Foucault’s ideas of governance need to be reworked or extended to adequately account for new algorithmic forms of regulating passengers and workers. My article could provide such a reworking, building on Foucault’s initial ideas to provide new theoretical tools that others can apply to their own case material. Such a piece will get accepted into high-ranking international journals due to its wider utility.
Level 4: uses the study of a phenomena to rethink a meta-concept or proposes a radically reworked or new theory. Here, the focus of attention shifts from how best to make sense of airport security to the meta-concept of governance, using the empirical case material to argue that it is not simply enough to extend Foucault’s thinking, rather a new way of thinking is required to adequately conceptualize how governance is being operationalised. Such new thinking tends to be well cited because it can generally be applied to making sense of lots of phenomena, such as the governance of schools, hospitals, workplaces, etc. Of course, Foucault consistently operated at this level, which is why he is so often reworked at Levels 2 and 3, and is one of the most impactful academics of his generation (cited nearly 42,000 time in 2013 alone). Writing a Level 4 piece requires a huge amount of skill, knowledge and insight, which is why so few academics work and publish at this level. Such pieces will be accepted into the very top ranked journals.
One way to think about this taxonomy is this: generally, those people who are the biggest names in their discipline, or across disciplines, have a solid body of published Level 3 and Level 4 material — this is why they are so well known; they produce material and ideas that have high transfer utility. Those people who well known within a sub-discipline generally have a body of Level 2 and Level 3 material. Those who are barely known outside of their national context generally have Level 1/2 profiles (and also have relatively small bodies of published work).
In my opinion, the majority of papers being published in international journals are Level 2/borderline 3 with some minor extension/reworking that has limited utility beyond making sense of a specific phenomena, or Level 3/borderline 2 with narrow, timid or uninspiring extension/reworking that constrains the paper’s broader appeal. Strong, bold Level 3 papers that have wider utility beyond the paper’s focus are less common, and Level 4 papers that really push the boundaries of thought and praxis are relatively rare. The majority of articles in national level journals tend to be Level 2; and the majority of book chapters in edited collections are Level 1 or 2. It is not uncommon, in my experience, for authors to think the paper that they have written is category above its real level (which is why they are often so disappointed with editor and referee reviews).
Does this basic taxonomy of impact work in practice?
I’ve not done a detailed empirical study, but can draw on two sources of observations. First, my experience as an editor two international journals (Progress in Human Geography, Dialogues in Human Geography), and for ten years an editor of another (Social and Cultural Geography), and viewing download rates and citational analysis for papers published in those journals. It is clear from such data that the relationship between level and citation generally holds — those papers that push boundaries and provide new thinking tend to be better cited. There are, of course, some exceptions and there are no doubt some Level 4 papers that are quite lowly cited for various reasons (e.g,, their arguments are ahead of their time), but generally the cream rises. Most academics intuitively know this, which is why the most consistent response of referees and editors to submitted papers is to provide feedback that might help shift Level 2/borderline Level 3 papers (which are the most common kind of submission) up to solid Level 3 papers – pieces that provide new ways of thinking and doing and provide fresh perspectives and insights.
Second, by examining my own body of published work. Figure 2 displays the citation rates of all of my published material (books, papers, book chapters) divided into the four levels. There are some temporal effects (such as more recently published work not having had time to be cited) and some outliers (in this case, a textbook and a coffee table book) but the relationship is quite clear, especially when just articles are examined (Figure 3) — the rate of citation increases across levels. (I’ve been fairly brutally honest in categorising my pieces and what’s striking to me personally is proportionally how few Level 3 and 4 pieces I’ve published, which is something for me to work on).
So what does this all mean?
Basically, if you want your work to have impact you should try to write articles that meet Level 3 and 4 criteria — that is, produce novel material that provides new ideas, tools, methods that others can apply in their own studies. Creating such pieces is not easy or straightforward and demands a lot of reading, reflection and thinking, which is why it can be so difficult to get papers accepted into the top journals and the citation distribution curve is so heavily skewed, with a relatively small number of pieces having nearly all the citations (Figure 4 shows the skewing for my papers; my top cited piece has the same number of cites as the 119 pieces with the least number).
Figure 4: Skewed distribution of citations
In my experience, papers with zero citations are nearly all Level 1 and 2 pieces. That’s not the only kind of papers you should be striving to publish if you want some impact from your work.

 A Character Accesses City Infrastructure and Data in Watch Dogs
A Character Accesses City Infrastructure and Data in Watch Dogs The Control Centre in Rio de Janeiro
The Control Centre in Rio de Janeiro